Introduction
Floresta is a collection of Rust libraries designed for building a Bitcoin full node, alongside the assembled daemon and RPC client binaries, all developed by Davidson Souza.
A key feature of Floresta is its use of the utreexo accumulator to maintain the UTXO set in a highly compact format. It also incorporates innovative techniques to significantly reduce Initial Block Download (IBD) times with minimal security tradeoffs.
The Utreexo accumulator consists of a forest of merkle trees where leaves are individual UTXOs, thus the name U-Tree-XO. The UTXO set at any moment is represented as the merkle roots of the forest.
The novelty in this cryptographic system is a mechanism to update the forest, both adding new UTXOs and deleting existing ones from the set. When a transaction spends UTXOs we can verify it with an inclusion proof, and then delete those specific UTXOs from the set.
Currently, the node can only operate in pruned mode, meaning it deletes block data after validation. Combined with utreexo, this design keeps storage requirements exceptionally low (< 1 GB).
The ultimate vision for Floresta is to deliver a reliable and ultra-lightweight node implementation capable of running on low-resource devices, democratizing the access to the Bitcoin blockchain. However, keep in mind that Floresta remains highly experimental software ⚠️.
About This Book
This documentation provides an overview of the process involved in creating and running a Floresta node (i.e., a UtreexoNode). We start by examining the project's overall structure, which is necessary to build a foundation for understanding its internal workings.
The book will contain plenty of code snippets, which are identical to Floresta code sections. Each snippet includes a commented path referencing its corresponding file, visible by clicking the eye icon in the top-right corner of the snippet (e.g., // Path: floresta-chain/src/lib.rs).
You will also find some interactive quizzes to test and reinforce your understanding of Floresta!
Note on Types
To avoid repetitive explanations, this documentation follows a simple convention: unless otherwise stated any mentioned type is assumed to come from the bitcoin crate, which provides many of the building blocks for Floresta. If you see a type, and we don't mention its source, you can assume it's a bitcoin type.
Project Overview
The Floresta project is made up of a few library crates, providing modular node and application components, and two binaries: florestad, the Floresta daemon (i.e., the assembled node implementation), and floresta-cli, the command-line interface for florestad.
Developers can use the core components in the libraries to build their own wallets and node implementations. They can use individual libraries or use the whole pack of components with the floresta meta-crate, which just re-exports libraries.
Components of Floresta
At the heart of Floresta are two fundamental libraries:
floresta-chain, which validates the blockchain and maintains node state.floresta-wire, which connects to the Bitcoin network, fetching transactions and blocks to advance the chain.
A useful way to picture the role of these two libraries is with a car analogy:
A full node is like a self-driving car that must keep up with a constantly moving destination, as new blocks are produced. The Bitcoin network is the road.
floresta-wireis the car's sensors and navigation, reading the road ahead.floresta-chainis the engine and control system, deciding how to move forward. Withoutfloresta-wire, the engine has no data to act on; withoutfloresta-chain, the car cannot move.
These two crates share building blocks from floresta-common (a small common library). Together, they form the minimum needed for a functioning node. On top of them, utilities extend functionality:
floresta-watch-only: a watch-only wallet backend for tracking addresses and balances.floresta-compact-filters: builds and queries BIP-158 filters to speed wallet rescans and enable UTXO lookups. This is especially useful as Floresta is fully pruned.floresta-electrum: an Electrum server that answers wallet-oriented queries (headers, balances, UTXOs, transactions) for external clients.
Finally, we find a meta-crate that re-exports these components, and two libraries that power the floresta-cli and florestad binaries:
floresta- A meta-crate that re-exports the previous modular components.
floresta-rpc- Provides the JSON-RPC API and types used by the CLI, powering
floresta-cli.
- Provides the JSON-RPC API and types used by the CLI, powering
floresta-node- Implements the node functionality by assembling all the components. This crate is the "glue layer" between the modular crates and the daemon binary (
florestadwill just invoke the logic implemented here).
- Implements the node functionality by assembling all the components. This crate is the "glue layer" between the modular crates and the daemon binary (
UtreexoNode
UtreexoNode is the top-level type in Floresta, responsible for managing P2P connections, receiving network data, and broadcasting transactions. All its logic is found at the floresta-wire crate.
Blocks fetched by UtreexoNode are passed to a blockchain backend for validation and state tracking. This backend is represented by a generic Chain type. Additionally, UtreexoNode relies on a separate generic Context type to provide context-specific behavior. The default Context is RunningNode, which handles the transition between other contexts (it's the highest level context).
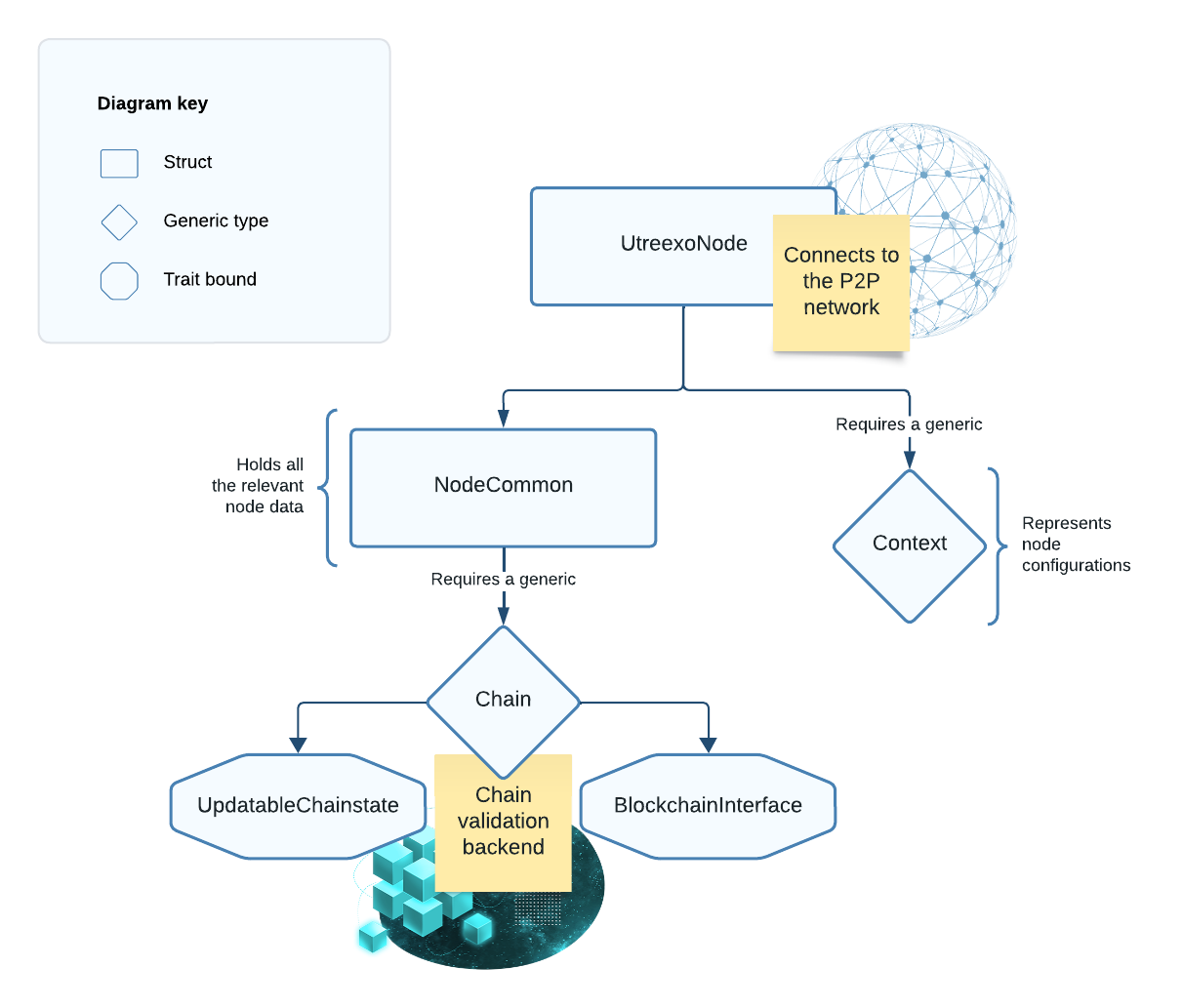
Figure 1: Diagram of the UtreexoNode type.
Below is the actual type definition, which is a struct with two fields and trait bounds for the Chain backend.
Filename: floresta-wire/src/p2p_wire/node.rs
// Path: floresta-wire/src/p2p_wire/node.rs
pub struct UtreexoNode<Chain: ChainBackend, Context = RunningNode> {
pub(crate) common: NodeCommon<Chain>,
pub(crate) context: Context,
}The Chain backend must implement the ChainBackend trait, which is just shorthand for the two key traits that define the backend.
// Path: floresta-chain/src/pruned_utreexo/mod.rs
pub trait ChainBackend: BlockchainInterface + UpdatableChainstate {}Each trait defines a distinct responsibility of our blockchain backend:
UpdatableChainstate: Methods to update the state of the blockchain backend.BlockchainInterface: Defines the interface for interacting with other components, such asUtreexoNode.
Both traits are located in the floresta-chain library crate, in src/pruned_utreexo/mod.rs.
In the next section, we will explore the required API for these traits.
Chain Backend API
We will now take a look at the API that the Chain backend (from UtreexoNode) is required to expose, as part of the BlockchainInterface and UpdatableChainstate traits.
The lists below are only meant to provide an initial sense of the expected chain API.
The BlockchainInterface Trait
The BlockchainInterface methods are mainly about getting information from the current view of the blockchain and state of validation.
It defines a generic associated error type bounded by the std::error::Error trait—or, in no-std environments, by Floresta's own minimal Error marker trait—so each BlockchainInterface implementation can pick its own error type.
The list of required methods:
get_block_hash, given a u32 height.get_tx, given its txid.get_heightof the chain.broadcasta transaction to the network.estimate_feefor inclusion in usize target blocks.get_block, given its hash.get_best_blockhash and height.get_block_header, given its hash.is_in_ibd, whether we are in Initial Block Download (IBD) or not.get_unbroadcastedtransactions.is_coinbase_mature, given its block hash and height (on the mainchain, coinbase transactions mature after 100 blocks).get_block_locator, i.e., a compact list of block hashes used to efficiently identify the most recent common point in the blockchain between two nodes for synchronization purposes.get_block_locator_for_tip, given the hash of the tip block. This can be used for tips that are not canonical or best.get_validation_index, i.e., the height of the last block we have validated.get_block_height, given its block hash.get_chain_tipsblock hashes, including the best tip and non-canonical ones.get_fork_point, to get the block hash where a given branch forks (the branch is represented by its tip block hash).get_params, to get the parameters for chain consensus.acc, to get the current utreexo accumulator.
Also, we have a subscribe method which allows other components to receive notifications of new validated blocks from the blockchain backend.
Filename: floresta-chain/src/pruned_utreexo/mod.rs
// Path: floresta-chain/src/pruned_utreexo/mod.rs
pub trait BlockchainInterface {
type Error: Error + Send + Sync + 'static;
// ...
fn get_block_hash(&self, height: u32) -> Result<bitcoin::BlockHash, Self::Error>;
fn get_tx(&self, txid: &bitcoin::Txid) -> Result<Option<bitcoin::Transaction>, Self::Error>;
fn get_height(&self) -> Result<u32, Self::Error>;
fn broadcast(&self, tx: &bitcoin::Transaction) -> Result<(), Self::Error>;
fn estimate_fee(&self, target: usize) -> Result<f64, Self::Error>;
fn get_block(&self, hash: &BlockHash) -> Result<Block, Self::Error>;
fn get_best_block(&self) -> Result<(u32, BlockHash), Self::Error>;
fn get_block_header(&self, hash: &BlockHash) -> Result<BlockHeader, Self::Error>;
fn subscribe(&self, tx: Arc<dyn BlockConsumer>);
// ...
fn is_in_ibd(&self) -> bool;
fn get_unbroadcasted(&self) -> Vec<Transaction>;
fn is_coinbase_mature(&self, height: u32, block: BlockHash) -> Result<bool, Self::Error>;
fn get_block_locator(&self) -> Result<Vec<BlockHash>, Self::Error>;
fn get_block_locator_for_tip(&self, tip: BlockHash) -> Result<Vec<BlockHash>, BlockchainError>;
fn get_validation_index(&self) -> Result<u32, Self::Error>;
fn get_block_height(&self, hash: &BlockHash) -> Result<Option<u32>, Self::Error>;
fn update_acc(
&self,
acc: Stump,
block: Block,
height: u32,
proof: Proof,
del_hashes: Vec<sha256::Hash>,
) -> Result<Stump, Self::Error>;
fn get_chain_tips(&self) -> Result<Vec<BlockHash>, Self::Error>;
fn validate_block(
&self,
block: &Block,
proof: Proof,
inputs: HashMap<OutPoint, UtxoData>,
del_hashes: Vec<sha256::Hash>,
acc: Stump,
) -> Result<(), Self::Error>;
fn get_fork_point(&self, block: BlockHash) -> Result<BlockHash, Self::Error>;
fn get_params(&self) -> bitcoin::params::Params;
fn acc(&self) -> Stump;
}// Path: floresta-chain/src/pruned_utreexo/mod.rs
pub enum Notification {
NewBlock((Block, u32)),
}Any type that implements the BlockConsumer trait can subscribe to our BlockchainInterface by passing a reference of itself, and receive notifications of new blocks (including block data and height). In the future this can be extended to also notify transactions.
Validation Methods
Finally, there are two validation methods that do NOT update the node state:
update_acc, to get the new accumulator after applying a new block. It requires the current accumulator, the new block data, the inclusion proof for the spent UTXOs, and the hashes of the spent UTXOs.validate_block, which instead of only verifying the inclusion proof, validates the whole block (including its transactions, for which the spent UTXOs themselves are needed).
The UpdatableChainstate Trait
On the other hand, the methods required by UpdatableChainstate are expected to update the node state.
These methods use the BlockchainError enum, found in pruned_utreexo/error.rs. Each variant of BlockchainError represents a kind of error that is expected to occur (block validation errors, invalid utreexo proofs, etc.). The UpdatableChainstate methods are:
Very important
connect_block: Takes a block and utreexo data, validates the block and adds it to our chain.accept_header: Checks a header and saves it in storage. This is called beforeconnect_block, which is responsible for accepting or rejecting the actual block.
// Path: floresta-chain/src/pruned_utreexo/mod.rs
pub trait UpdatableChainstate {
fn connect_block(
&self,
block: &Block,
proof: Proof,
inputs: HashMap<OutPoint, UtxoData>,
del_hashes: Vec<sha256::Hash>,
) -> Result<u32, BlockchainError>;
// ...
fn switch_chain(&self, new_tip: BlockHash) -> Result<(), BlockchainError>;
fn accept_header(&self, header: BlockHeader) -> Result<(), BlockchainError>;
// ...
fn handle_transaction(&self) -> Result<(), BlockchainError>;
fn flush(&self) -> Result<(), BlockchainError>;
fn toggle_ibd(&self, is_ibd: bool);
fn invalidate_block(&self, block: BlockHash) -> Result<(), BlockchainError>;
fn mark_block_as_valid(&self, block: BlockHash) -> Result<(), BlockchainError>;
fn get_root_hashes(&self) -> Vec<BitcoinNodeHash>;
fn get_partial_chain(
&self,
initial_height: u32,
final_height: u32,
acc: Stump,
) -> Result<PartialChainState, BlockchainError>;
fn mark_chain_as_assumed(&self, acc: Stump, tip: BlockHash) -> Result<bool, BlockchainError>;
fn get_acc(&self) -> Stump;
}Usually, in IBD we fetch a chain of headers with sufficient PoW first, and only then do we ask for the block data (i.e., the transactions) in order to verify the blocks. This way we ensure that DoS attacks sending our node invalid blocks, with the purpose of wasting our resources, are costly because of the required PoW.
Others
switch_chain: Reorg to another branch, given its tip block hash.handle_transaction: Process transactions that are in the mempool.flush: Writes pending data to storage. Should be invoked periodically.toggle_ibd: Toggle the IBD process on/off.invalidate_block: Tells the blockchain backend to consider this block invalid.mark_block_as_valid: Overrides a block that was marked as invalid, considering it as fully validated.get_root_hashes: Returns the root hashes of our utreexo accumulator.get_partial_chain: Returns aPartialChainState(a Floresta type allowing to validate parts of the chain in parallel, explained in Chapter 5), given the height range and the initial utreexo state.mark_chain_as_assumed: Given a block hash and the corresponding accumulator, assume every ancestor block is valid.get_acc: Returns the current accumulator.
Using ChainState as Chain Backend
Recall that
UtreexoNodeis the high-level component of Floresta that will interact with the P2P network. It is made of itsContextand aNodeCommonthat holds aChainbackend (for validation and state tracking). This and the following chapters will focus solely on the Floresta chain backend.
In this chapter we will learn about ChainState, a type that implements UpdatableChainstate + BlockchainInterface, so we can use it as Chain backend.
ChainState is the default blockchain backend provided by Floresta, with all its logic encapsulated within the floresta-chain library.
The following associations clarify the module structure:
UtreexoNodedeclaration and logic resides infloresta-wireChainStatedeclaration and logic resides infloresta-chain
ChainState Structure
The job of
ChainStateis to validate blocks, update the state and store it.
For a node to keep track of the chain state effectively, it is important to ensure the state is persisted to some sort of storage system. This way the node progress is saved, and we can recover it after the device is turned off.
That's why ChainState uses a generic PersistedState type, bounded by the ChainStore trait, which defines how we interact with our persistent state database.
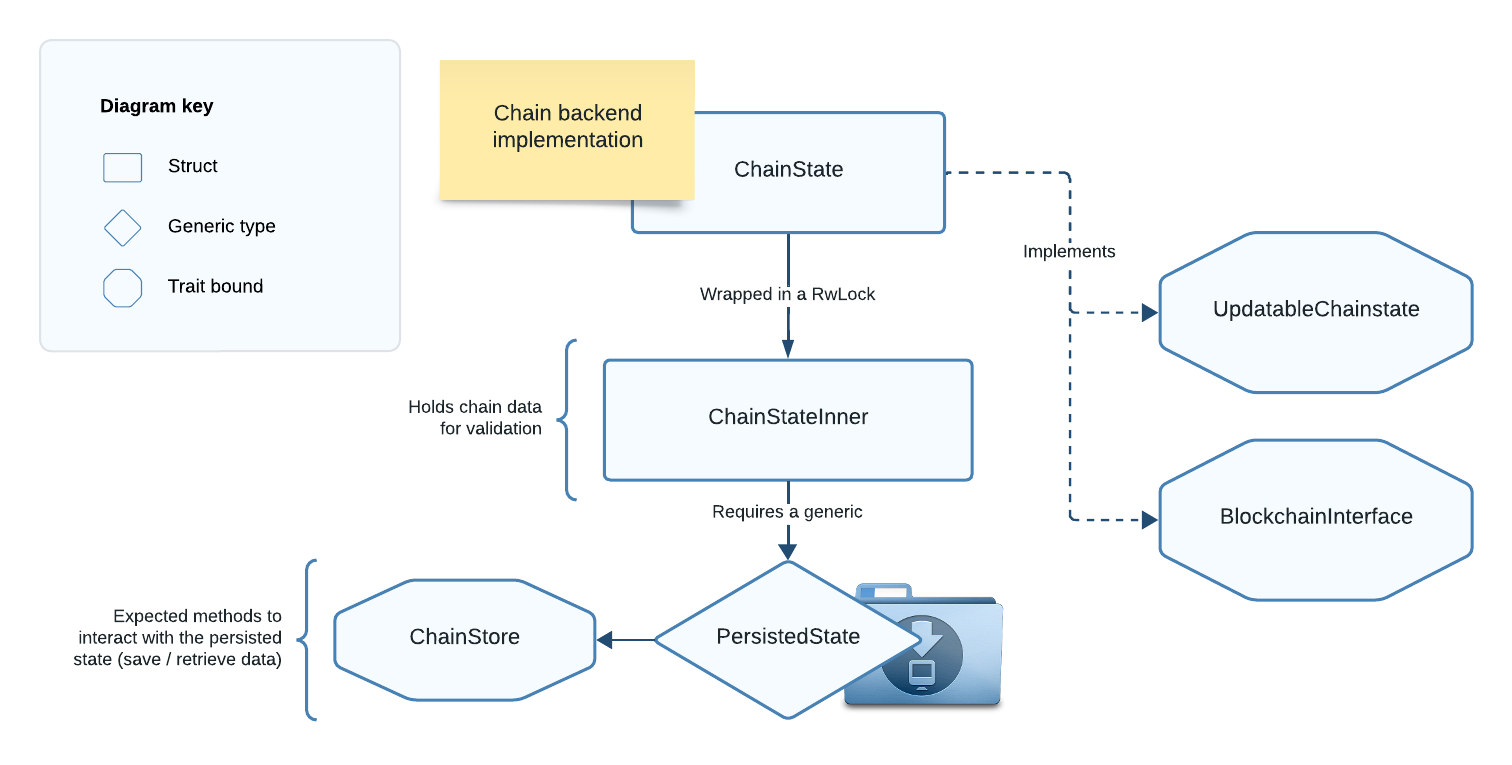
Figure 2: Diagram of the ChainState type.
Filename: pruned_utreexo/chain_state.rs
// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
pub struct ChainState<PersistedState: ChainStore> {
inner: RwLock<ChainStateInner<PersistedState>>,
}// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
impl<PersistedState: ChainStore> BlockchainInterface for ChainState<PersistedState> {
// Implementation of BlockchainInterface for ChainState// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
impl<PersistedState: ChainStore> UpdatableChainstate for ChainState<PersistedState> {
// Implementation of UpdatableChainstate for ChainStateAs Floresta is currently only pruned, the expected database primarily consists of the block header chain and the utreexo accumulator; blocks themselves are not stored.
The default implementation of ChainStore is FlatChainStore, but we also provide a simpler KvChainStore implementation. This means that developers may:
- Implement custom
UpdatableChainstate + BlockchainInterfacetypes for use asChainbackends. - Use the provided
ChainStatebackend:- With their own
ChainStoreimplementation. - Or the provided
FlatChainStoreorKvChainStoreimplementations.
- With their own
Next, let’s build the ChainState struct step by step!
The ChainStore Trait
ChainStoreis a trait that abstracts the persistent storage layer for the FlorestaChainStatebackend.
To create a ChainState, we start by building its ChainStore implementation.
ChainStore API
The methods required by ChainStore, designed for interaction with persistent storage, are:
save_roots_for_block/load_roots_for_block: Save or load the utreexo accumulator (merkle roots) that results after processing a particular block.save_height/load_height: Save or load the current chain tip data.save_header/get_header: Save or retrieve a block header by itsBlockHash.get_block_hash/update_block_index: Retrieve or associate aBlockHashwith a chain height.flush: Immediately persist saved data still in memory. This ensures data recovery in case of a crash.check_integrity: Performs a database integrity check. This can be a no-op if our implementation leverages a database crate that ensures integrity.
In other words, the implementation of these methods should allow us to save and load:
- The accumulator for each block (serialized as a
Vec<u8>), such that we can reorg our UTXO set if a fork becomes the best chain. - The current chain tip data (as
BestChain). - Block headers (as
DiskBlockHeader), associated to the block hash. - Block hashes (as
BlockHash), associated with a height.
BestChain and DiskBlockHeader are important Floresta types that we will see in a minute. DiskBlockHeader represents stored block headers, while BestChain tracks the chain tip metadata.
With this data we have a pruned view of the blockchain, metadata about the chain we are in, and the compact UTXO set (the utreexo accumulator).
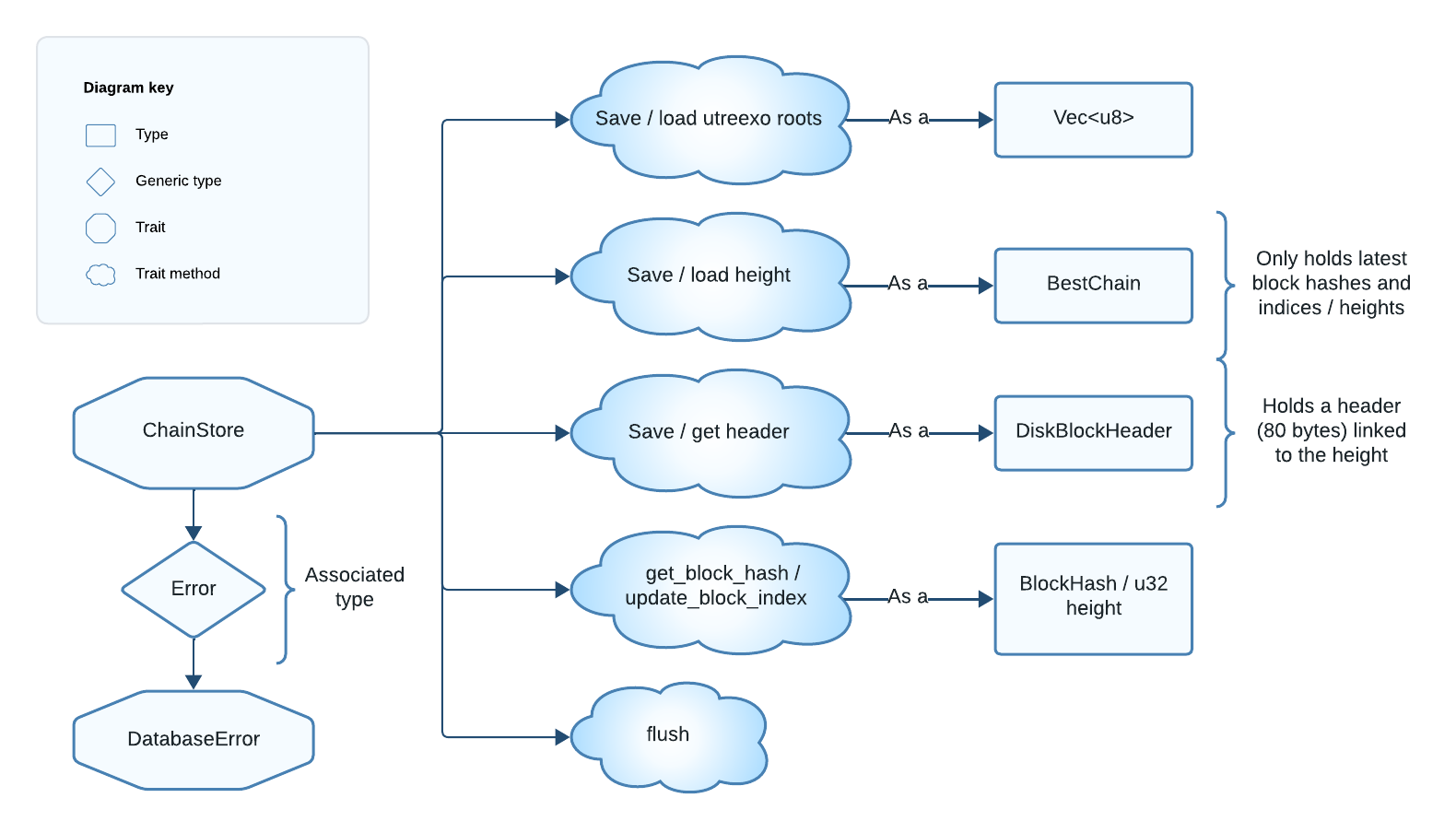
Figure 3: Diagram of the ChainStore trait.
ChainStore also has an associated Error type for the methods:
Filename: pruned_utreexo/chainstore.rs
// Path: floresta-chain/src/pruned_utreexo/chainstore.rs
pub trait ChainStore {
type Error: DatabaseError;
fn save_roots_for_block(&mut self, roots: Vec<u8>, height: u32) -> Result<(), Self::Error>;
// ...
fn load_roots_for_block(&mut self, height: u32) -> Result<Option<Vec<u8>>, Self::Error>;
fn load_height(&self) -> Result<Option<BestChain>, Self::Error>;
fn save_height(&mut self, height: &BestChain) -> Result<(), Self::Error>;
fn get_header(&self, block_hash: &BlockHash) -> Result<Option<DiskBlockHeader>, Self::Error>;
fn get_header_by_height(&self, height: u32) -> Result<Option<DiskBlockHeader>, Self::Error>;
fn save_header(&mut self, header: &DiskBlockHeader) -> Result<(), Self::Error>;
fn get_block_hash(&self, height: u32) -> Result<Option<BlockHash>, Self::Error>;
fn flush(&mut self) -> Result<(), Self::Error>;
fn update_block_index(&mut self, height: u32, hash: BlockHash) -> Result<(), Self::Error>;
fn check_integrity(&self) -> Result<(), Self::Error>;
}Hence, implementations of ChainStore are free to use any error type as long as it implements DatabaseError. This is just a marker trait that can be automatically implemented on any T: std::error::Error + std::fmt::Display. This flexibility allows compatibility with different database implementations.
Now, let's do a brief overview of the two provided ChainStore implementations.
FlatChainStore and KvChainStore
Floresta currently offers two ChainStore implementations. The first available implementation, and by far the simplest one, is KvChainStore, which wraps the kv crate (itself a thin layer over sled) to provide a key-value embedded database store.
The second one is FlatChainStore, which replaced KvChainStore as the default store. Nowadays, florestad will compile by default with this store, but you can still use the old KvChainStore if you compile it with --no-default-features --features kv-chainstore. However, FlatChainStore was designed to deliver optimal performance, especially on low-resource devices like smartphones.
Instead of using key-value buckets, FlatChainStore keeps all the data in raw .bin files. Then, we create a memory-map that allows us to read and write to these files as if they were in memory. Once initialized, it has the following directory structure:
chaindata/
├─ headers.bin # mmap‑ed header vector
├─ fork_headers.bin # mmap‑ed header vector for fork chains
├─ blocks_index.bin # mmap‑ed vector<u32>, accessed via a hash‑map linking block hashes to heights
│
├─ accumulators.bin # plain file (roots blob, var‑len records)
└─ metadata.bin # mmap‑ed Metadata struct (version, checksums, file lengths...)For more detailed information about FlatChainStore, see Apendix A.
And that's all for this section! Next we will see two important types used to store and retrieve data via the ChainStore methods: BestChain and DiskBlockHeader.
BestChain and DiskBlockHeader
As previously mentioned, BestChain and DiskBlockHeader are Floresta types used for storing and retrieving data in the ChainStore database.
DiskBlockHeader
We use a custom DiskBlockHeader instead of the direct bitcoin::block::Header to add some metadata:
Filename: pruned_utreexo/chainstore.rs
// Path: floresta-chain/src/pruned_utreexo/chainstore.rs
// BlockHeader is an alias for bitcoin::block::Header
pub enum DiskBlockHeader {
FullyValid(BlockHeader, u32),
AssumedValid(BlockHeader, u32),
Orphan(BlockHeader),
HeadersOnly(BlockHeader, u32),
InFork(BlockHeader, u32),
InvalidChain(BlockHeader),
}DiskBlockHeader not only holds a header but also encodes possible block states, as well as the height when it makes sense.
When we start downloading headers in IBD we save them as HeadersOnly. If a header doesn't have a parent, it's saved as Orphan. If it's not in the best chain, InFork. And when we validate the actual blocks we should be able to mark the headers as FullyValid.
Also, we have AssumeValid for a configuration that allows the node to skip script validation, and InvalidChain for cases when UpdatableChainstate::invalidate_block is called.
BestChain
The BestChain struct is an internal representation of the chain we are in and has the following fields:
best_block: The current best chain's lastBlockHash(the actual block may or may not have been validated yet).depth: The number of blocks pilled after the genesis block (i.e., the height of the tip).validation_index: TheBlockHashup to which we have validated the chain.alternative_tips: A vector of fork tipBlockHashes with a chance of becoming the best chain.
Filename: pruned_utreexo/chainstore.rs
// Path: floresta-chain/src/pruned_utreexo/chainstore.rs
pub struct BestChain {
pub best_block: BlockHash,
pub depth: u32,
pub validation_index: BlockHash,
pub alternative_tips: Vec<BlockHash>,
}Building the ChainState
The next step is building the ChainState struct, which validates blocks and updates the ChainStore.
Filename: pruned_utreexo/chain_state.rs
// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
pub struct ChainState<PersistedState: ChainStore> {
inner: RwLock<ChainStateInner<PersistedState>>,
}Note that the RwLock that we use to wrap ChainStateInner is not the one from the standard library but from the spin crate, thus allowing no_std.
std::sync::RwLockrelies on the OS to block and wake threads when the lock is available, whilespin::RwLockuses a spinlock which does not require OS support for thread management, as the thread simply keeps running (and checking for lock availability) instead of sleeping.
The builder for ChainState has this signature:
// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
pub fn new(
mut chainstore: PersistedState,
network: Network,
assume_valid: AssumeValidArg,
) -> ChainState<PersistedState> {The first argument is our ChainStore implementation, the second one is the Network enum from the bitcoin crate, and thirdly the AssumeValidArg enum.
The Network enum acknowledges four kinds of networks: Bitcoin (mainchain), Testnet (version 3), Testnet4, Signet and Regtest.
The Assume-Valid Lore
The assume_valid argument refers to a Bitcoin Core option that allows nodes during IBD to assume the validity of scripts (mainly signatures) up to a certain block.
Nodes with this option enabled will still choose the most PoW chain (the best tip), and will only skip script validation if the Assume-Valid block is in that chain. Otherwise, if the Assume-Valid block is not in the best chain, they will validate everything.
When users use the default
Assume-Validhash, hardcoded in the software, they aren't blindly trusting script validity. These hashes are reviewed through the same open-source process as other security-critical changes in Bitcoin Core, so the trust model is unchanged.
In Bitcoin Core, the hardcoded Assume-Valid block hash is included in src/kernel/chainparams.cpp.
Filename: pruned_utreexo/chain_state.rs
// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
pub enum AssumeValidArg {
Disabled,
Hardcoded,
UserInput(BlockHash),
}Disabled means the node verifies all scripts, Hardcoded means the node uses the default block hash that has been hardcoded in the software (and validated by maintainers, developers and reviewers), and UserInput means using a hash that the node runner provides, although the validity of the scripts up to this block should have been externally validated.
Genesis and Assume-Valid Blocks
The first part of the body of ChainState::new (let's omit the impl block from now on):
// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
pub fn new(
mut chainstore: PersistedState,
network: Network,
assume_valid: AssumeValidArg,
) -> ChainState<PersistedState> {
let parameters = network.into();
let genesis = genesis_block(¶meters);
chainstore
.save_header(&DiskBlockHeader::FullyValid(genesis.header, 0))
.expect("Error while saving genesis");
chainstore
.update_block_index(0, genesis.block_hash())
.expect("Error updating index");
let assume_valid = ChainParams::get_assume_valid(network, assume_valid);
// ...
ChainState {
inner: RwLock::new(ChainStateInner {
chainstore,
acc: Stump::new(),
best_block: BestChain {
best_block: genesis.block_hash(),
depth: 0,
validation_index: genesis.block_hash(),
alternative_tips: Vec::new(),
},
broadcast_queue: Vec::new(),
subscribers: Vec::new(),
fee_estimation: (1_f64, 1_f64, 1_f64),
ibd: true,
consensus: Consensus { parameters },
assume_valid,
}),
}
}First, we use the genesis_block function from bitcoin to retrieve the genesis block based on the specified parameters, which are determined by the Network kind.
Then we save the genesis header into chainstore, which of course is FullyValid and has height 0. We also link the index 0 with the genesis block hash.
Finally, we get an Option<BlockHash> by calling the ChainParams::get_assume_valid function, which takes a Network and an AssumeValidArg.
Filename: pruned_utreexo/chainparams.rs
// Path: floresta-chain/src/pruned_utreexo/chainparams.rs
// Omitted: impl ChainParams {
pub fn get_assume_valid(network: Network, arg: AssumeValidArg) -> Option<BlockHash> {
match arg {
AssumeValidArg::Disabled => None,
AssumeValidArg::UserInput(hash) => Some(hash),
AssumeValidArg::Hardcoded => match network {
Network::Bitcoin => Some(bhash!(
"00000000000000000001ff36aef3a0454cf48887edefa3aab1f91c6e67fee294"
)),
Network::Testnet => Some(bhash!(
"000000007df22db38949c61ceb3d893b26db65e8341611150e7d0a9cd46be927"
)),
Network::Testnet4 => Some(bhash!(
"0000000000335c2895f02ebc75773d2ca86095325becb51773ce5151e9bcf4e0"
)),
Network::Signet => Some(bhash!(
"000000084ece77f20a0b6a7dda9163f4527fd96d59f7941fb8452b3cec855c2e"
)),
Network::Regtest => Some(bhash!(
"0f9188f13cb7b2c71f2a335e3a4fc328bf5beb436012afca590b1a11466e2206"
)),
},
}
}The final part of ChainState::new just returns the instance of ChainState with the ChainStateInner initialized. We will see this initialization next.
Initializing ChainStateInner
This is the struct that holds the meat of the matter (or should we say the root of the issue). As it's inside the spin::RwLock it can be read and modified in a thread-safe way. Its fields are:
acc: The accumulator, of typeStump(which comes from therustreexocrate).chainstore: Our implementation ofChainStore.best_block: Of typeBestChain.broadcast_queue: Holds a list of transactions to be broadcast, of typeVec<Transaction>.subscribers: A vector of trait objects (different types allowed) that implement theBlockConsumertrait, indicating they want to get notified when a new valid block arrives.fee_estimation: Fee estimation for the next 1, 10 and 20 blocks, as a tuple of three f64.ibd: A boolean indicating if we are in IBD.consensus: Parameters for the chain validation, as aConsensusstruct (a Floresta type that will be explained in detail in Chapter 4).assume_valid: As anOption<BlockHash>.
Note that the accumulator and the best block data are kept in our ChainStore, but we cache them in ChainStateInner for faster access, avoiding potential disk reads and deserializations (e.g., loading them from the meta bucket if we use KvChainStore).
Let's next see how these fields are accessed with an example.
Adding Subscribers to ChainState
As ChainState implements BlockchainInterface, it has a subscribe method to allow other types receive notifications.
The subscribers are stored in the ChainStateInner.subscribers field, but we need to handle the RwLock that wraps ChainStateInner for that.
Filename: pruned_utreexo/chain_state.rs
// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
// Omitted: impl<PersistedState: ChainStore> BlockchainInterface for ChainState<PersistedState> {
fn subscribe(&self, tx: Arc<dyn BlockConsumer>) {
let mut inner = self.inner.write();
inner.subscribers.push(tx);
}This is the BlockchainInterface::subscribe implementation. We use the write method on the RwLock which then gives us exclusive access to the ChainStateInner.
When inner is dropped after the push, the lock is released and becomes available for other threads, which may acquire write access (one thread at a time) or read access (multiple threads simultaneously).
Initial ChainStateInner Values
In ChainState::new we initialize ChainStateInner like so:
// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
pub fn new(
mut chainstore: PersistedState,
network: Network,
assume_valid: AssumeValidArg,
) -> ChainState<PersistedState> {
let parameters = network.into();
let genesis = genesis_block(¶meters);
chainstore
.save_header(&DiskBlockHeader::FullyValid(genesis.header, 0))
.expect("Error while saving genesis");
chainstore
.update_block_index(0, genesis.block_hash())
.expect("Error updating index");
let assume_valid = ChainParams::get_assume_valid(network, assume_valid);
// ...
ChainState {
inner: RwLock::new(ChainStateInner {
chainstore,
acc: Stump::new(),
best_block: BestChain {
best_block: genesis.block_hash(),
depth: 0,
validation_index: genesis.block_hash(),
alternative_tips: Vec::new(),
},
broadcast_queue: Vec::new(),
subscribers: Vec::new(),
fee_estimation: (1_f64, 1_f64, 1_f64),
ibd: true,
consensus: Consensus { parameters },
assume_valid,
}),
}
}The TLDR is that we move chainstore to the ChainStateInner, initialize the accumulator (Stump::new), initialize BestChain with the genesis block (being the best block and best validated block) and depth 0, initialize broadcast_queue and subscribers as empty vectors, set the minimum fee estimations, set ibd to true, use the Consensus parameters for the current Network and move the assume_valid optional hash in.
Recap
In this chapter we have understood the structure of ChainState, a type implementing UpdatableChainstate + BlockchainInterface; a blockchain backend. This type required a ChainStore implementation, expected to save state data to disk, and we examined the provided KvChainStore.
Finally, we have seen the ChainStateInner struct, which keeps track of the ChainStore and more data.
We can now build a ChainState as simply as:
fn main() {
let chain_store =
KvChainStore::new("./epic_location".to_string())
.expect("failed to open the blockchain database");
let chain = ChainState::new(
chain_store,
Network::Bitcoin,
AssumeValidArg::Disabled,
);
}State Transition and Validation
With the ChainState struct built, the foundation for running a node, we can now dive into the methods that validate and apply state transitions.
ChainState has 4 impl blocks (all located in pruned_utreexo/chain_state.rs):
- The
BlockchainInterfacetrait implementation - The
UpdatableChainstatetrait implementation - The implementation of other methods and associated functions like
ChainState::new - The conversion from
ChainStateBuilder(builder type located in pruned_utreexo/chain_state_builder.rs) toChainState
The entry point to the state transition and validation logic are the accept_header and connect_block methods from UpdatableChainstate. As we have explained previously, the first step in the IBD is accepting headers, so we will start with that.
Accepting Headers
The full accept_header method implementation for ChainState is below. To get read or write access to the ChainStateInner we use two macros, read_lock and write_lock.
In short, the method takes a bitcoin::block::Header (type alias BlockHeader) and accepts it on top of our header chain, or maybe reorgs if it's extending a better chain (i.e., switching to the new better chain). If there's an error it returns BlockchainError, which we mentioned in The UpdatableChainstate Trait subsection from Chapter 1.
// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
fn accept_header(&self, header: BlockHeader) -> Result<(), BlockchainError> {
let disk_header = self.get_disk_block_header(&header.block_hash());
match disk_header {
Err(e @ BlockchainError::Database(_)) => {
// If there's a database error we don't know if we already
// have the header or not
return Err(e);
}
Ok(found) => {
// Possibly reindex to recompute the best_block field
self.maybe_reindex(&found)?;
// We already have this header
return Ok(());
}
_ => (),
}
// The best block we know of
let best_block = self.get_best_block()?;
// Do validation in this header
let block_hash = self.validate_header(&header)?;
// Update our current tip
if header.prev_blockhash == best_block.1 {
let height = best_block.0 + 1;
debug!("Header builds on top of our best chain");
write_lock!(self).best_block.new_block(block_hash, height);
let disk_header = DiskBlockHeader::HeadersOnly(header, height);
self.update_header_and_index(&disk_header, block_hash, height)?;
} else {
debug!("Header not in the best chain");
self.maybe_reorg(header)?;
}
Ok(())
}First, we check if we already have the header in our database. We query it with the get_disk_block_header method, which just wraps ChainStore::get_header in order to return BlockchainError (instead of T: DatabaseError).
If get_disk_block_header returns Err it may be because the header was not in the database or because there was a DatabaseError. In the latter case, we propagate the error.
We have the header
If we already have the header in our database we may reindex, which means recomputing the BestChain struct, and return Ok early.
Reindexing updates the
best_blockfield if it is not up-to-date with the disk headers (for instance, having headers up to the 105th, butbest_blockonly referencing the 100th). This happens when the node is turned off or crashes before persisting the latestBestChaindata.
We don't have the header
If we don't have the header, then we get the best block hash and height (with BlockchainInterface::get_best_block) and perform a simple validation on the header with validate_header. If validation passes, we potentially update the current tip.
- If the new header extends the previous best block:
- We update the
best_blockfield, adding the new block hash and height. - Then we call
save_headerandupdate_block_indexto update the database, via theupdate_header_and_indexhelper.
- We update the
- If the header doesn't extend the current best chain, we may reorg if it extends a better chain.
Reindexing
During IBD, headers arrive rapidly, making it pointless to write the BestChain data to disk for every new header. Instead, we update the ChainStateInner.best_block field and only persist it occasionally, avoiding redundant writes that would be instantly overridden.
But there is a possibility that the node is shut down or crashes before save_height is called (or before the pending write is completed) and after the headers have been written to disk. In this case we can recompute the last BestChain data by going through the headers on disk. This recovery process is handled by the reindex_chain method within maybe_reindex.
// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
fn maybe_reindex(&self, potential_tip: &DiskBlockHeader) -> Result<(), BlockchainError> {
// Check if the disk header is an unvalidated block in the best chain
if let DiskBlockHeader::HeadersOnly(_, height) = potential_tip {
let best_height = self.get_best_block()?.0;
// If the best chain height is lower, it needs to be updated
if *height > best_height {
warn!("Found block with height {height}, while the current best chain is at {best_height}. Reindexing.");
self.reindex_chain()?;
}
}
Ok(())
}We call reindex_chain if disk header's height > best_block's height, as it means that best_block is not up to date with the headers on disk.
Validate Header
The validate_header method takes a BlockHeader and performs the following checks:
Check the header chain
- Retrieve the previous
DiskBlockHeader. If not found, returnBlockchainError::BlockNotPresentorBlockchainError::Database. - If the previous
DiskBlockHeaderis marked asOrphanorInvalidChain, returnBlockchainError::BlockValidation.
Check the PoW
- Use the
get_next_required_workmethod to compute the expected PoW target and compare it with the header's actual target. If the actual target is easier, returnBlockchainError::BlockValidation. - Check the special BIP 94 rules for the Testnet 4 network.
- Verify the PoW against the target using a
bitcoinmethod. If verification fails, returnBlockchainError::BlockValidation.
// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
fn validate_header(&self, block_header: &BlockHeader) -> Result<BlockHash, BlockchainError> {
let prev_block = self.get_disk_block_header(&block_header.prev_blockhash)?;
let height = prev_block
.height()
.ok_or(BlockValidationErrors::BlockExtendsAnOrphanChain)?
+ 1;
// ...
// Check pow
let expected_target = self.get_next_required_work(&prev_block, height, block_header)?;
let actual_target = block_header.target();
if actual_target > expected_target {
return Err(BlockValidationErrors::NotEnoughPow)?;
}
self.check_bip94_block(block_header, height)?;
let block_hash = block_header
.validate_pow(actual_target)
.map_err(|_| BlockValidationErrors::NotEnoughPow)?;
Ok(block_hash)
}A block header passing this validation will not make the block itself valid, but we can use this to build the chain of headers with verified PoW.
Reorging the Chain
In the accept_header method we have seen that, when receiving a header that doesn't extend the best chain, we may reorg. This is done with the maybe_reorg method.
We have to choose between the two branches, represented by:
branch_tip: The last header from the alternative chain.current_tip: The last header from the current best chain.
// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
fn maybe_reorg(&self, branch_tip: BlockHeader) -> Result<(), BlockchainError> {
let current_tip = self.get_block_header(&self.get_best_block()?.1)?;
self.check_branch(&branch_tip)?;
let current_work = self.get_branch_work(¤t_tip)?;
let new_work = self.get_branch_work(&branch_tip)?;
// If the new branch has more work, it becomes the new best chain
if new_work > current_work {
self.reorg(branch_tip)?;
return Ok(());
}
// If the new branch has less work, we just store it as an alternative branch
// that might become the best chain in the future.
self.push_alt_tip(&branch_tip)?;
let parent_height = self.get_ancestor(&branch_tip)?.try_height()?;
self.update_header(&DiskBlockHeader::InFork(branch_tip, parent_height + 1))?;
Ok(())
}We first call the check_branch method to check if we know all the branch_tip ancestors. In other words, we check if branch_tip is indeed part of a branch, which requires that no ancestor is Orphan.
Then we get the work in each chain tip with get_branch_work and do the following:
- We reorg to the
branch_tipif it has more work, and returnOkearly. - Else if
branch_tipdoesn't have more work we push its hash tobest_block.alternative_tipsvia thepush_alt_tipmethod and save the header asInFork.
The push_alt_tip method just checks if the branch_tip parent hash is in alternative_tips to remove it, as it's no longer the tip of the branch. Then we simply push the branch_tip hash.
Reorg
Let's now dig into reorg logic, with reorg. We start by querying the best block hash and use it to query its header. Then we get the header where the branch forks out with find_fork_point.
// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
fn reorg(&self, new_tip: BlockHeader) -> Result<(), BlockchainError> {
let current_best_block = self.get_block_header(&self.get_best_block()?.1)?;
let fork_point = self.find_fork_point(&new_tip)?;
self.mark_chain_as_inactive(¤t_best_block, fork_point.block_hash())?;
self.mark_chain_as_active(&new_tip, fork_point.block_hash())?;
let validation_index = self.get_last_valid_block(&new_tip)?;
let depth = self.get_chain_depth(&new_tip)?;
self.change_active_chain(&new_tip, validation_index, depth);
self.reorg_acc(&fork_point)?;
Ok(())
}We use mark_chain_as_inactive and mark_chain_as_active to update the disk data (i.e., marking the previous InFork headers as HeadersOnly and vice versa, and linking the height indexes to the new branch block hashes).
Then we invoke get_last_valid_block and get_chain_depth to obtain said data from a branch, provided the branch header tip.
Note that we don't validate forks unless they become the best chain, so in this case the last validated block is the last common block between the two branches.
With this data we call change_active_chain to update the best_block field. We also call reorg_acc to roll back to the saved accumulator for the new last validated block, which is needed to proceed with the new branch validation.
// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
fn change_active_chain(&self, new_tip: &BlockHeader, last_valid: BlockHash, depth: u32) {
let mut inner = self.inner.write();
inner.best_block.best_block = new_tip.block_hash();
inner.best_block.validation_index = last_valid;
inner.best_block.depth = depth;
}Connecting Blocks
Great! At this point we should have a sense of the inner workings of accept_headers. Let's now understand the connect_block method, which performs the actual block validation and updates the ChainStateInner fields and database. This function is meant to increase our chain validation index, and so it requires to be called on the right block (i.e., the next one to validate).
connect_block takes a Block, an UTXO set inclusion Proof from rustreexo, the UTXOs to spend (stored with metadata in a custom floresta type called UtxoData) and the hashes from said outputs. If result is Ok the function returns the height.
// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
fn connect_block(
&self,
block: &Block,
proof: Proof,
inputs: HashMap<OutPoint, UtxoData>,
del_hashes: Vec<sha256::Hash>,
) -> Result<u32, BlockchainError> {
let header = self.get_disk_block_header(&block.block_hash())?;
let height = match header {
DiskBlockHeader::FullyValid(_, height) => {
let validation_index = self.get_validation_index()?;
// If this block is not our validation index, but the caller is trying to connect
// it, this is a logical error, and we will have spurious errors, specially with
// invalid proof. They don't mean the block is invalid, just that we are using the
// wrong accumulator, since we are not processing the right block.
if height != validation_index {
return Err(BlockValidationErrors::BlockDoesntExtendTip)?;
}
// If this block is our validation index, but it's fully valid, this clearly means
// there was some corruption of our state. If we don't process this block, we will
// be stuck forever.
//
// Note: You may think "just kick the validation index one block further and we are
// good". But this is not the case, because we still need to update our
// accumulator. Otherwise, the next block will always have an invalid proof
// (because the accumulator is not updated).
height
},
// Our called tried to connect_block on a block that is not the next one in our chain
DiskBlockHeader::Orphan(_)
| DiskBlockHeader::AssumedValid(_, _) // this will be validated by a partial chain
| DiskBlockHeader::InFork(_, _)
| DiskBlockHeader::InvalidChain(_) => return Err(BlockValidationErrors::BlockExtendsAnOrphanChain)?,
DiskBlockHeader::HeadersOnly(_, height) => {
let validation_index = self.get_validation_index()?;
// In case of a `HeadersOnly` block, we need to check if the height is
// the next one after the validation index. If not, we would be trying to
// connect a block where our accumulator isn't the right one. So the proof will
// always be invalid.
if height != validation_index + 1 {
return Err(BlockValidationErrors::BlockDoesntExtendTip)?;
}
height
}
};
// Clone inputs only if a subscriber wants spent utxos
let inputs_for_notifications = self
.inner
.read()
.subscribers
.iter()
.any(|subscriber| subscriber.wants_spent_utxos())
.then(|| inputs.clone());
self.validate_block_no_acc(block, height, inputs)?;
let acc = Consensus::update_acc(&self.acc(), block, height, proof, del_hashes)?;
self.update_view(height, &block.header, acc)?;
info!(
"New tip! hash={} height={height} tx_count={}",
block.block_hash(),
block.txdata.len()
);
#[cfg(feature = "metrics")]
metrics::get_metrics().block_height.set(height.into());
if !self.is_in_ibd() || height % 100_000 == 0 {
self.flush()?;
}
// Notify others we have a new block
self.notify(block, height, inputs_for_notifications.as_ref());
Ok(height)
}When we call connect_block, the header should already be stored on disk, as accept_header is called first. Then we will verify we are calling the function for the right block.
If the header is FullyValid it means we already validated the block, and we only try to re-connect the block if it's the last validated block (i.e., the validation index), which could be needed if some of our data was lost. Else if the header is Orphan, AssumeValid, InFork or InvalidChain we return an error, as this means our block is not mainchain or doesn't require validation.
If header is HeadersOnly, meaning the block is an unvalidated mainchain block, we will check it is the next one to validate. Thus, if we validated up to block h, then we must call connect_block for block h + 1 (this is because we can only use the accumulator at height h to validate the block h + 1).
So, when block is the next block to validate, or it is the validation index, we go on to validate it using validate_block_no_acc, and then the Consensus::update_acc function, which verifies the inclusion proof against the accumulator and returns the updated accumulator.
After this, we have fully validated the block! The next steps in connect_block are updating the state and notifying the block to subscribers.
Post-Validation
After block validation we call update_view to mark the disk header as FullyValid (ChainStore::save_header), update the block hash index (ChainStore::update_block_index) and also update ChainStateInner.acc and the validation index of best_block.
Then, we call UpdatableChainstate::flush every 100,000 blocks during IBD or for each new block once synced. In order, this method invokes:
save_acc, which serializes the accumulator and callsChainStore::save_rootsChainStore::save_heightChainStore::flush, to immediately flush to disk all pending writes
// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
fn flush(&self) -> Result<(), BlockchainError> {
let mut inner = write_lock!(self);
let best_block = inner.best_block.clone();
inner.chainstore.save_height(&best_block)?;
inner.chainstore.flush()?;
Ok(())
}Last of all, we notify the new validated block to subscribers.
Block Validation
We have arrived at the final part of this chapter! Here we understand the validate_block_no_acc method that we used in connect_block, and lastly do a recap of everything.
validate_block_no_accis also used inside theBlockchainInterface::validate_blocktrait method implementation, as it encapsulates the non-utreexo validation logic.The difference between
UpdatableChainstate::connect_blockandBlockchainInterface::validate_blockis that the first is used during IBD, while the latter is a tool that allows the node user to validate blocks without affecting the node state.
The method returns BlockchainError::BlockValidation, wrapping many different BlockValidationErrors, which is an enum declared in pruned_utreexo/errors.rs.
// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
pub fn validate_block_no_acc(
&self,
block: &Block,
height: u32,
inputs: HashMap<OutPoint, UtxoData>,
) -> Result<(), BlockchainError> {
if !block.check_merkle_root() {
return Err(BlockValidationErrors::BadMerkleRoot)?;
}
let bip34_height = self.chain_params().params.bip34_height;
// If bip34 is active, check that the encoded block height is correct
if height >= bip34_height && self.get_bip34_height(block) != Some(height) {
return Err(BlockValidationErrors::BadBip34)?;
}
if !block.check_witness_commitment() {
return Err(BlockValidationErrors::BadWitnessCommitment)?;
}
if block.weight().to_wu() > 4_000_000 {
return Err(BlockValidationErrors::BlockTooBig)?;
}
// Validate block transactions
let subsidy = read_lock!(self).consensus.get_subsidy(height);
let verify_script = self.verify_script(height)?;
#[cfg(feature = "bitcoinconsensus")]
let flags = read_lock!(self)
.consensus
.parameters
.get_validation_flags(height, block.block_hash());
#[cfg(not(feature = "bitcoinconsensus"))]
let flags = 0;
Consensus::verify_block_transactions(
height,
inputs,
&block.txdata,
subsidy,
verify_script,
flags,
)?;
Ok(())
}In order, we do the following things:
- Call
check_merkle_rooton theblock, to check that the merkle root commits to all the transactions. - Check that if the height is greater or equal than that of the activation of BIP 34, the coinbase transaction encodes the height as specified.
- Call
check_witness_commitment, to check that thewtxidmerkle root is included in the coinbase transaction as per BIP 141. - Finally, check that the block weight doesn't exceed the 4,000,000 weight unit limit.
Lastly, we go on to validate the transactions. We retrieve the current subsidy (the newly generated coins) with the get_subsidy method on our Consensus struct. We also call the verify_script method which returns a boolean flag indicating if we are NOT inside the Assume-Valid range.
// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
fn verify_script(&self, height: u32) -> Result<bool, PersistedState::Error> {
let inner = self.inner.read();
match inner.assume_valid {
Some(hash) => {
match inner.chainstore.get_header(&hash)? {
// If the assume-valid block is in the best chain, only verify scripts if we are higher
Some(DiskBlockHeader::HeadersOnly(_, assume_h))
| Some(DiskBlockHeader::FullyValid(_, assume_h)) => Ok(height > assume_h),
// Assume-valid is not in the best chain, so verify all the scripts
_ => Ok(true),
}
}
None => Ok(true),
}
}We also get the validation flags for the current height with get_validation_flags, only if the bitcoinconsensus feature is active. These flags are used to validate transactions taking into account the different consensus rules that have been added over time.
And lastly we call the Consensus::verify_block_transactions associated function.
Recap
In this chapter we have seen many of the methods for the ChainState type, mainly related to the chain validation and state transition process.
We started with accept_header, that checked if the header was in the database or not. If it was in the database we just called maybe_reindex. If it was not, we validated it and potentially updated the chain tip, either by extending it or by reorging. We also called ChainStore::save_header and ChainStore::update_block_index.
Then we saw connect_block, which validated the next block in the chain with validate_block_no_acc. If block was valid, we may invoke UpdatableChainstate::flush to persist all data (including the data saved with ChainStore::save_roots and ChainStore::save_height) and also marked the disk header as FullyValid. Finally, we notified the new block.
Consensus and bitcoinconsensus
In the previous chapter, we saw that the block validation process involves two associated functions from Consensus:
verify_block_transactions: The last check performed insidevalidate_block_no_acc, after having validated the two merkle roots and height commitment.update_acc: Called insideconnect_block, just aftervalidate_block_no_acc, to verify the utreexo proof and get the updated accumulator.
The Consensus struct only holds a parameters field (as we saw when we initialized ChainStateInner) and provides a few core consensus functions. In this chapter we are going to see the two mentioned functions and discuss the details of how we verify scripts.
Filename: pruned_utreexo/consensus.rs
// Path: floresta-chain/src/pruned_utreexo/consensus.rs
pub struct Consensus {
// The chain parameters are in the chainparams.rs file
pub parameters: ChainParams,
}bitcoinconsensus
Consensus::verify_block_transactions is a critical part of Floresta, as it validates all the transactions in a block. One of the hardest parts for validation is checking the script satisfiability, that is, verifying whether the inputs can indeed spend the coins. It's also the most resource-intensive part of block validation, as it requires verifying many digital signatures.
Implementing a Bitcoin script interpreter is challenging, and given the complexity of both C++ and Rust, we cannot be certain that it will always behave in the same way as Bitcoin Core. This is problematic because if our Rust implementation rejects a script that Bitcoin Core accepts, our node will fork from the network. It will treat subsequent blocks as invalid, halting synchronization with the chain and being unable to continue tracking the user balance.
Partly because of this reason, in 2015 the script validation logic of Bitcoin Core was extracted and placed into the libbitcoin-consensus library. This library includes 35 files that are identical to those of Bitcoin Core. Subsequently, the library API was bound to Rust in rust-bitcoinconsensus, which serves as the bitcoinconsensus feature-dependency in the bitcoin crate.
If this feature is set, bitcoin provides a verify_with_flags method on Transaction, which performs the script validation by calling C++ code extracted from Bitcoin Core. Floresta uses this method to verify scripts.
libbitcoinkernel
bitcoinconsensushandles only script validation and is maintained as a separate project fromBitcoin Core, with limited upkeep.To address these shortcomings there's an ongoing effort within the
Bitcoin Corecommunity to extract the whole consensus engine into a library. This is known as the libbitcoinkernel project.Once this is achieved, we should be able to drop all the consensus code in Floresta and replace the
bitcoinconsensusdependency with the Rust bindings for the new library. This would make Floresta safer and more reliable as a full node.
Transaction Validation
Let's now dive into Consensus::verify_block_transactions, to see how we verify the transactions in a block. As we saw in the Block Validation section from last chapter, this function takes the height, the UTXOs to spend, the spending transactions, the current subsidy, the verify_script boolean (which was only true when we are not in the Assume-Valid range) and the validation flags.
// Path: floresta-chain/src/pruned_utreexo/chain_state.rs
pub fn validate_block_no_acc(
&self,
block: &Block,
height: u32,
inputs: HashMap<OutPoint, UtxoData>,
) -> Result<(), BlockchainError> {
if !block.check_merkle_root() {
return Err(BlockValidationErrors::BadMerkleRoot)?;
}
let bip34_height = self.chain_params().params.bip34_height;
// If bip34 is active, check that the encoded block height is correct
if height >= bip34_height && self.get_bip34_height(block) != Some(height) {
return Err(BlockValidationErrors::BadBip34)?;
}
if !block.check_witness_commitment() {
return Err(BlockValidationErrors::BadWitnessCommitment)?;
}
if block.weight().to_wu() > 4_000_000 {
return Err(BlockValidationErrors::BlockTooBig)?;
}
// Validate block transactions
let subsidy = read_lock!(self).consensus.get_subsidy(height);
let verify_script = self.verify_script(height)?;
// ...
#[cfg(feature = "bitcoinconsensus")]
let flags = read_lock!(self)
.consensus
.parameters
.get_validation_flags(height, block.block_hash());
#[cfg(not(feature = "bitcoinconsensus"))]
let flags = 0;
Consensus::verify_block_transactions(
height,
inputs,
&block.txdata,
subsidy,
verify_script,
flags,
)?;
Ok(())
}Validation Flags
The validation flags were returned by get_validation_flags based on the current height and block hash, and they are of type core::ffi::c_uint: a foreign function interface type used for the C++ bindings.
// Path: floresta-chain/src/pruned_utreexo/chainparams.rs
// Omitted: impl ChainParams {
#[cfg(feature = "bitcoinconsensus")]
/// Returns the validation flags for a given block hash and height
pub fn get_validation_flags(&self, height: u32, hash: BlockHash) -> c_uint {
if let Some(flag) = self.exceptions.get(&hash) {
return *flag;
}
// From Bitcoin Core:
// BIP16 didn't become active until Apr 1 2012 (on mainnet, and
// retroactively applied to testnet)
// However, only one historical block violated the P2SH rules (on both
// mainnet and testnet).
// Similarly, only one historical block violated the TAPROOT rules on
// mainnet.
// For simplicity, always leave P2SH+WITNESS+TAPROOT on except for the two
// violating blocks.
let mut flags = bitcoinconsensus::VERIFY_P2SH | bitcoinconsensus::VERIFY_WITNESS;
if height >= self.params.bip65_height {
flags |= bitcoinconsensus::VERIFY_CHECKLOCKTIMEVERIFY;
}
if height >= self.params.bip66_height {
flags |= bitcoinconsensus::VERIFY_DERSIG;
}
if height >= self.csv_activation_height {
flags |= bitcoinconsensus::VERIFY_CHECKSEQUENCEVERIFY;
}
if height >= self.segwit_activation_height {
flags |= bitcoinconsensus::VERIFY_NULLDUMMY;
}
flags
}The flags cover the following consensus rules added to Bitcoin over time:
- P2SH (BIP 16): Activated at height 173,805
- Enforce strict DER signatures (BIP 66): Activated at height 363,725
- CHECKLOCKTIMEVERIFY (BIP 65): Activated at height 388,381
- CHECKSEQUENCEVERIFY (BIP 112): Activated at height 419,328
- Segregated Witness (BIP 141) and Null Dummy (BIP 147): Activated at height 481,824
Verify Block Transactions
Now, the Consensus::verify_block_transactions function has this body, which in turn calls Consensus::verify_transaction:
Filename: pruned_utreexo/consensus.rs
// Path: floresta-chain/src/pruned_utreexo/consensus.rs
// Omitted: impl Consensus {
/// Verify if all transactions in a block are valid. Here we check the following:
/// - The block must contain at least one transaction, and this transaction must be coinbase
/// - The first transaction in the block must be coinbase
/// - The coinbase transaction must have the correct value (subsidy + fees)
/// - The block must not create more coins than allowed
/// - All transactions must be valid, as verified by [`Consensus::verify_transaction`]
#[allow(unused)]
pub fn verify_block_transactions(
height: u32,
mut utxos: HashMap<OutPoint, UtxoData>,
transactions: &[Transaction],
subsidy: u64,
verify_script: bool,
flags: c_uint,
) -> Result<(), BlockchainError> {
// Blocks must contain at least one transaction (i.e., the coinbase)
if transactions.is_empty() {
return Err(BlockValidationErrors::EmptyBlock)?;
}
// Total block fees that the miner can claim in the coinbase
let mut fee = 0;
for (n, transaction) in transactions.iter().enumerate() {
if n == 0 {
if !transaction.is_coinbase() {
return Err(BlockValidationErrors::FirstTxIsNotCoinbase)?;
}
Self::verify_coinbase(transaction)?;
// Skip next checks: coinbase input is exempt, coinbase reward checked later
continue;
}
// Actually verify the transaction
let (in_value, out_value) =
Self::verify_transaction(transaction, &mut utxos, height, verify_script, flags)?;
// Fee is the difference between inputs and outputs
fee += in_value - out_value;
}
// Check coinbase output values to ensure the miner isn't producing excess coins
let allowed_reward = fee + subsidy;
let coinbase_total: u64 = transactions[0]
.output
.iter()
.map(|out| out.value.to_sat())
.sum();
if coinbase_total > allowed_reward {
return Err(BlockValidationErrors::BadCoinbaseOutValue)?;
}
Ok(())
}
/// Verifies a single, non-coinbase transaction. To verify (the structure of) a coinbase
/// transaction, use [`Consensus::verify_coinbase`].
///
/// This function checks that the transaction:
/// - Has at least one input and one output
/// - Doesn't have null PrevOuts (reserved only for coinbase transactions)
/// - Doesn't spend more coins than it claims in the inputs
/// - Doesn't "move" more coins than allowed (at most 21 million)
/// - Spends mature coins, in case any input refers to a coinbase transaction
/// - Has valid scripts (if we don't assume them), and within the allowed size
pub fn verify_transaction(
transaction: &Transaction,
utxos: &mut HashMap<OutPoint, UtxoData>,
height: u32,
_verify_script: bool,
_flags: c_uint,
) -> Result<(u64, u64), BlockchainError> {
let txid = || transaction.compute_txid();
if transaction.input.is_empty() {
return Err(tx_err!(txid, EmptyInputs))?;
}
if transaction.output.is_empty() {
return Err(tx_err!(txid, EmptyOutputs))?;
}
let out_value: u64 = transaction
.output
.iter()
.map(|out| out.value.to_sat())
.sum();
let mut in_value = 0;
for input in transaction.input.iter() {
// Null PrevOuts are only allowed in coinbase inputs
if input.previous_output.is_null() {
return Err(tx_err!(txid, NullPrevOut))?;
}
let utxo = Self::get_utxo(input, utxos, txid)?;
let txout = &utxo.txout;
// A coinbase output created at height n can only be spent at height >= n + 100
if utxo.is_coinbase && (height < utxo.creation_height + 100) {
return Err(tx_err!(txid, CoinbaseNotMatured))?;
}
// Check script sizes (spent txo pubkey, and current tx scriptsig and TODO witness)
Self::validate_script_size(&txout.script_pubkey, txid)?;
Self::validate_script_size(&input.script_sig, txid)?;
// TODO check also witness script size
in_value += txout.value.to_sat();
}
// Value in should be greater or equal to value out. Otherwise, inflation.
if out_value > in_value {
return Err(tx_err!(txid, NotEnoughMoney))?;
}
// Sanity check
if out_value > 21_000_000 * COIN_VALUE {
return Err(BlockValidationErrors::TooManyCoins)?;
}
// Verify the tx script
#[cfg(feature = "bitcoinconsensus")]
if _verify_script {
transaction
.verify_with_flags(
|outpoint| utxos.remove(outpoint).map(|utxo| utxo.txout),
_flags,
)
.map_err(|e| tx_err!(txid, ScriptValidationError, format!("{e:?}")))?;
};
Ok((in_value, out_value))
}In general, the function behavior is well explained in the comments. Something to note is that we need the bitcoinconsensus feature set in order to compile verify_with_flags and verify the transaction scripts. Because this method is just a C++ call behind the scenes, we make it optional for some architectures to compile the Floresta crates without C++ support.
We also don't validate if verify_script is false, but this is because the Assume-Valid process has already assessed the scripts as valid.
Note that these consensus checks are far from complete. More checks will be added in the short term, but once libbitcoinkernel bindings are ready this function will instead use them.
Utreexo Validation
In the previous section we have seen the Consensus::verify_block_transactions function. It was taking a utxos argument, used to verify that each transaction input satisfies the script of the UTXO it spends, and that transactions spend no more than the sum of input amounts.
However, we have yet to verify that these utxos actually exist in the UTXO set, i.e., check that nobody is spending coins out of thin air. That's what we are going to do inside Consensus::update_acc, and get the updated UTXO set accumulator, with spent UTXOs removed and new ones added.
Recall that
Stumpis the type of our accumulator, coming from therustreexocrate.Stumprepresents the merkle roots of a forest where leaves are UTXO hashes.
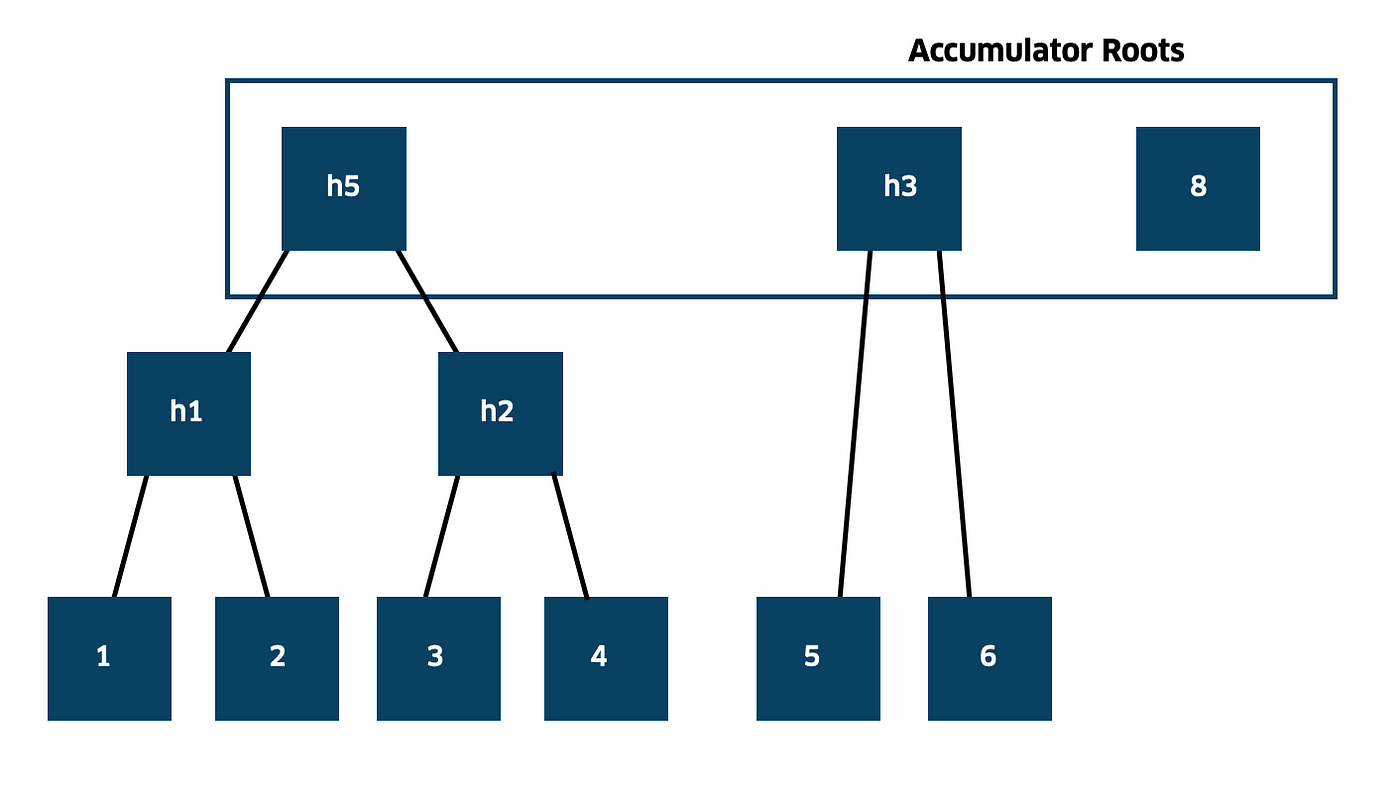
Figure 4: A visual depiction of the utreexo forest. To prove that UTXO 4 is part of the set we provide the hash of UTXO 3 and h1. With this data we can re-compute the h5 root, which must be identical. Credit: original utreexo post.
This function first verifies we are not spending any of the two historical unspendable UTXOs according to BIP 30. In the early days of Bitcoin there were two occurrences of duplicate transaction IDs, which override the previous UTXO with the same transaction ID. Because utreexo leaf hashes commit to more data, we don't see the previous UTXO as overridden, so we need to enforce it is unspendable manually.
// Path: floresta-chain/src/pruned_utreexo/consensus.rs
// Omitted: impl Consensus {
pub fn update_acc(
acc: &Stump,
block: &Block,
height: u32,
proof: Proof,
del_hashes: Vec<sha256::Hash>,
) -> Result<Stump, BlockchainError> {
let block_hash = block.block_hash();
// Check if there is a spend of an unspendable UTXO (BIP30)
if Self::contains_unspendable_utxo(&del_hashes) {
return Err(BlockValidationErrors::UnspendableUTXO)?;
}
// Convert to BitcoinNodeHash, from rustreexo
let del_hashes: Vec<_> = del_hashes.into_iter().map(Into::into).collect();
let adds = udata::proof_util::get_block_adds(block, height, block_hash);
// Update the accumulator
let acc = acc.modify(&adds, &del_hashes, &proof)?.0;
Ok(acc)
}Then we get the new leaf hashes (the hashes of newly created UTXOs in the block) by calling udata::proof_util::get_block_adds. This function returns the new leaves to add to the accumulator, which exclude two cases:
- Created UTXOs that are provably unspendable (i.e., an OP_RETURN output or any output with a script larger than 10,000 bytes).
- Created UTXOs spent within the same block.
Finally, we get the updated Stump using its modify method, provided the leaves to add, the leaves to remove and the proof of inclusion for the latter. This method both verifies the proof and generates the new accumulator.
Advanced Chain Validation Methods
Before moving on from floresta-chain to floresta-wire, it's time to understand some advanced validation methods and another Chain backend provided by Floresta: the PartialChainState.
Although similar to ChainState, PartialChainState focuses on validating a limited range of blocks rather than the entire chain. This design is closely linked to concepts like UTXO snapshots (precomputed UTXO states at specific blocks) and, in particular, out-of-order validation, which we’ll explore below.
Out-of-Order Validation
One of the most powerful features enabled by utreexo is out-of-order validation, which allows block intervals to be validated independently if we know the utreexo roots at the start of each interval.
In traditional IBDs, block validation is inherently sequential: a block at height h depends on the UTXO set resulting from block h - 1, which in turn depends on h - 2, and so forth. However, with UTXO set snapshots for specific blocks, validation can become non-linear.
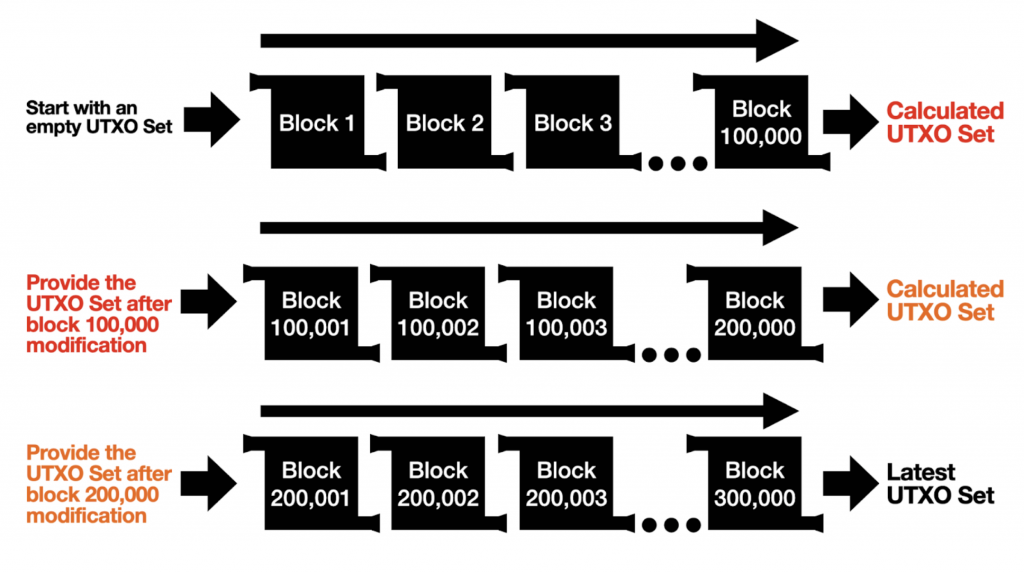
Figure 5: Visual explanation of three block intervals, starting at block 1, 100,001, and 200,001, that can be validated in parallel if we have the UTXO sets for those blocks. Credit: original post from Calvin Kim.
This process remains fully trustless because, at the end, we verify that the resulting UTXO set from one interval matches the UTXO set snapshot used to start the next. For example, in the image, the UTXO set after block 100,000 must match the set used for the interval beginning at block 100,001, and so on.
Ultimately, the sequential nature of block validation is preserved. The worst outcome is wasting resources if the UTXO snapshots are incorrect, so it's still important to obtain these snapshots from a reliable source, such as hardcoded values within the software or reputable peers.
Out-of-Order Validation Without Utreexo
Out-of-order validation is technically possible without utreexo, but it would require entire UTXO sets for each interval, which would take many gigabytes.
Utreexo makes this feasible with compact accumulators, avoiding the need for full UTXO set storage and frequent disk reads. Instead, spent UTXOs are fetched on demand from the network, along with their inclusion proofs.
Essentially, we are trading disk operations for hash computations (by verifying merkle proofs and updating roots), along with a slightly higher network data demand. In other words, utreexo enables parallel validation while avoiding the bottleneck of slow disk access.
Trusted UTXO Set Snapshots
A related but slightly different concept is the Assume-Utxo feature in Bitcoin Core, which hardcodes a trusted, recent UTXO set hash. When a new node starts syncing, it downloads the corresponding UTXO set from the network, verifies its hash against the hardcoded value, and temporarily assumes it to be valid. Starting from this snapshot, the node can quickly sync to the chain tip (e.g., if the snapshot is from block 850,000 and the tip is at height 870,000, only 20,000 blocks need to be validated to get a synced node).
This approach bypasses most of the IBD time, enabling rapid node synchronization while still silently completing IBD in the background to fully validate the UTXO set snapshot. It builds on the Assume-Valid concept, relying on the open-source process to ensure the correctness of hardcoded UTXO set hashes.
This idea, adapted to Floresta, is what we call Assume-Utreexo, a hardcoded UTXO snapshot in the form of utreexo roots. These hardcoded values are located in pruned_utreexo/chainparams.rs, alongside the Assume-Valid hashes.
// Path: floresta-chain/src/pruned_utreexo/chainparams.rs
impl ChainParams {
pub fn get_assume_utreexo(network: Network) -> AssumeUtreexoValue {
let genesis = genesis_block(Params::new(network));
match network {
Network::Bitcoin => AssumeUtreexoValue {
block_hash: bhash!(
"0000000000000000000239f2b7f982df299193bdd693f499e6b893d8276ab7ce"
),
height: 902967,
roots: acchashes![
"bd53eef66849c9d3ca13b62ce694030ac4d4b484c6f490f473b9868a7c5df2e8",
"993ffb1782db628c18c75a5edb58d4d506167d85ca52273e108f35b73bb5b640",
"36d8c4ba5176c816bdae7c4119d9f2ea26a1f743f5e6e626102f66a835eaac6d",
"4c93092c1ecd843d2b439365609e7f616fe681de921a46642951cb90873ba6ce",
"9b4435987e18e1fe4efcb6874bba5cdc66c3e3c68229f54624cb6343787488a4",
"ab1e87c4066bf195fa7b8357874b82de4fa09ddba921499d6fc73aa133200505",
"8f8215e284dbce604988755ba3c764dbfa024ae0d9659cd67b24742f46360849",
"09b5057a8d6e1f61e93baf474220f581bd1a38d8a378dacb5f7fdec532f21e00",
"a331072d7015c8d33a5c17391264a72a7ca1c07e1f5510797064fced7fbe591d",
"c1c647289156980996d9ea46377e8c1b7e5c05940730ef8c25c0d081341221b5",
"330115a495ed14140cd785d44418d84b872480d293972abd66e3325fdc78ac93",
"b1d7a488e1197908efb2091a3b750508cb2fc495d2011bf2c34c5ae2d40bd2a5",
"3b3b2e51ad96e1ae8ce468c7947b8aa2b41ecb400a32edec3dbcfe5ddb9aca50",
"9d852775775f4c1e4a150404776a6b22569a0fe31f2e669fd3b31a0f70072800",
"8e5f6a92169ad67b3f2682f230e2a62fc849b0a47bc36af8ce6cae24a5343126",
"6dbd2925f8aa0745ac34fc9240ce2a7ef86953fc305c6570ef580a0763072bbe",
"8121c38dcb37684c6d50175f5fd2695af3b12ce0263d20eb7cc503b96f7dba0d",
"f5d8b30dd2038e1b3a5ced7a30c961e230270020c336fb649d0a9e169f11b876",
"0466bd4eb9e7be5b8870e97d2a66377525391c16f15dbcc3833853c8d3bae51e",
"976184c55f74cbb780938a20e2a5df2791cf51e712f68a400a6b024c77ad78e4",
]
.to_vec(),
leaves: 2860457445,
},
Network::Testnet => AssumeUtreexoValue {
// ...
block_hash: genesis.block_hash(),
height: 0,
leaves: 0,
roots: Vec::new(),
},
Network::Testnet4 => AssumeUtreexoValue {
// ...
block_hash: genesis.block_hash(),
height: 0,
leaves: 0,
roots: Vec::new(),
},
Network::Signet => AssumeUtreexoValue {
// ...
block_hash: genesis.block_hash(),
height: 0,
leaves: 0,
roots: Vec::new(),
},
Network::Regtest => AssumeUtreexoValue {
// ...
block_hash: genesis.block_hash(),
height: 0,
leaves: 0,
roots: Vec::new(),
},
}
}
// ...
pub fn get_assume_valid(network: Network, arg: AssumeValidArg) -> Option<BlockHash> {
match arg {
AssumeValidArg::Disabled => None,
AssumeValidArg::UserInput(hash) => Some(hash),
AssumeValidArg::Hardcoded => match network {
Network::Bitcoin => Some(bhash!(
"00000000000000000001ff36aef3a0454cf48887edefa3aab1f91c6e67fee294"
)),
Network::Testnet => Some(bhash!(
"000000007df22db38949c61ceb3d893b26db65e8341611150e7d0a9cd46be927"
)),
Network::Testnet4 => Some(bhash!(
"0000000000335c2895f02ebc75773d2ca86095325becb51773ce5151e9bcf4e0"
)),
Network::Signet => Some(bhash!(
"000000084ece77f20a0b6a7dda9163f4527fd96d59f7941fb8452b3cec855c2e"
)),
Network::Regtest => Some(bhash!(
"0f9188f13cb7b2c71f2a335e3a4fc328bf5beb436012afca590b1a11466e2206"
)),
},
}
}If you click see more, you will notice we have 17 utreexo roots there, and this is the accumulator for more than 2 billion UTXOs!
PoW Fraud Proofs Sync
PoW Fraud Proofs Sync is yet another technique to speedup node synchronization, which was ideated by Ruben Somsen. It is similar in nature to running a light or SPV client, but with almost the security of a full node. This is the most powerful IBD optimization that Floresta implements, alongside Assume-Utreexo.
The idea that underlies this type of sync is that we can treat blockchain forks as potential-fraud proofs. If a miner creates an invalid block (violating consensus rules), honest miners will not mine on top of such block. Instead, honest miners will fork the chain by mining an alternative, valid block at the same height.
As long as a small fraction of miners remains honest and produces at least one block, a non-validating observer can interpret blockchain forks as indicators of potentially invalid blocks, and will always catch any invalid block.
The PoW Fraud Proof sync process begins by identifying the most PoW chain, which only requires downloading block headers:
- If no fork is found, the node assumes the most PoW chain is valid and begins validating blocks starting close to the chain tip.
- If a fork is found, this suggests a potential invalid block in the most PoW chain (prompting honest miners to fork away). The node downloads and verifies the disputed block, which requires using the UTXO accumulator for that block. If valid, the node continues following the most PoW chain; if invalid, it switches to the alternative branch.
This method bypasses almost entirely the IBD verification while maintaining security. It relies on a small minority of honest hashpower (e.g., ~1%) to fork away from invalid chains, which we use to detect the invalid blocks.
In short, PoW Fraud Proofs Sync requires at least some valid blocks to be produced for invalid ones to be detected, whereas a regular full node, by validating every block, can detect invalid blocks even with 0% honest miners (though in that extreme case, the entire network would be in serious trouble 😄).
Hence, a PoW Fraud Proof synced node is vulnerable only when the Bitcoin chain is halted for an extended period of time, which would be catastrophic anyway. Check out this blog post by Davidson for more details.
Using PartialChainState as Chain Backend
As you may be guessing, PartialChainState is an alternative chain validation backend made to leverage the parallel sync feature we have described (out-of-order validation).
In the Chain Backend API section from Chapter 1 we saw that the UpdatableChainstate trait requires a get_partial_chain method.
// Path: floresta-chain/src/pruned_utreexo/mod.rs
pub trait UpdatableChainstate {
fn connect_block(
&self,
block: &Block,
proof: Proof,
inputs: HashMap<OutPoint, UtxoData>,
del_hashes: Vec<sha256::Hash>,
) -> Result<u32, BlockchainError>;
fn switch_chain(&self, new_tip: BlockHash) -> Result<(), BlockchainError>;
fn accept_header(&self, header: BlockHeader) -> Result<(), BlockchainError>;
fn handle_transaction(&self) -> Result<(), BlockchainError>;
fn flush(&self) -> Result<(), BlockchainError>;
fn toggle_ibd(&self, is_ibd: bool);
fn invalidate_block(&self, block: BlockHash) -> Result<(), BlockchainError>;
fn mark_block_as_valid(&self, block: BlockHash) -> Result<(), BlockchainError>;
fn get_root_hashes(&self) -> Vec<BitcoinNodeHash>;
// ...
fn get_partial_chain(
&self,
initial_height: u32,
final_height: u32,
acc: Stump,
) -> Result<PartialChainState, BlockchainError>;
// ...
fn mark_chain_as_assumed(&self, acc: Stump, tip: BlockHash) -> Result<bool, BlockchainError>;
fn get_acc(&self) -> Stump;
}The arguments that the method takes are indeed the block interval to validate and the accumulator at the start of the interval.
Just like ChainState, PartialChainState wraps an inner type which holds the actual data. However, instead of maintaining synchronization primitives, PartialChainState assumes that only a single worker (thread or async task) will hold ownership at any given time. This design expects workers to operate independently, with each validating its assigned partial chain. Once all partial chains are validated, we can transition to the ChainState backend.
Filename: pruned_utreexo/partial_chain.rs
// Path: floresta-chain/src/pruned_utreexo/partial_chain.rs
pub(crate) struct PartialChainStateInner {
/// The current accumulator state, it starts with a hardcoded value and
/// gets checked against the result of the previous partial chainstate.
pub(crate) current_acc: Stump,
/// The block headers in this interval, we need this to verify the blocks
/// and to build the accumulator. We assume this is sorted by height, and
/// should contain all blocks in this interval.
pub(crate) blocks: Vec<BlockHeader>,
/// The height we are on right now, this is used to keep track of the progress
/// of the sync.
pub(crate) current_height: u32,
/// The height we are syncing up to, trying to push more blocks than this will
/// result in an error.
pub(crate) final_height: u32,
/// The error that occurred during validation, if any. It is here so we can
/// pull that afterward.
pub(crate) error: Option<BlockValidationErrors>,
/// The consensus parameters, we need this to validate the blocks.
pub(crate) consensus: Consensus,
/// Whether we assume the signatures in this interval as valid, this is used to
/// speed up syncing, by assuming signatures in old blocks are valid.
pub(crate) assume_valid: bool,
}We can see that PartialChainStateInner has an assume_valid field. By combining the parallel sync with Assume-Valid we get a huge IBD speedup, with virtually no security trade-off. Most of the expensive script validations are skipped, while the remaining checks are performed in parallel and without disk access. In this IBD configuration, the primary bottleneck is likely network latency.
In the pruned_utreexo/partial_chain.rs file, we also find the BlockchainInterface and UpdatableChainstate implementations for PartialChainState. These implementations are similar to those for ChainState, but many methods remain unimplemented because PartialChainState is designed specifically for IBD and operates with limited data. For instance:
// Path: floresta-chain/src/pruned_utreexo/partial_chain.rs
fn accept_header(&self, _header: BlockHeader) -> Result<(), BlockchainError> {
unimplemented!("partialChainState shouldn't be used to accept new headers")
}Finally, there are very simple methods to get data from the status of validation of the partial chain:
// Path: floresta-chain/src/pruned_utreexo/partial_chain.rs
/// Returns whether any block inside this interval is invalid
pub fn has_invalid_blocks(&self) -> bool {
self.inner().error.is_some()
}Moving On
Now that we’ve explored the power of utreexo and how Floresta leverages it, along with:
- The structure of
floresta-chain, includingChainStateandPartialChainState. - The use of the
ChainStoretrait forChainState. - The consensus validation process.
We are now ready to fully delve into floresta-wire: the chain provider.
UtreexoNode In-Depth
We have already explored most of the floresta-chain crate! Now, it’s time to dive into the higher-level UtreexoNode, first introduced in the utreexonode section of Chapter 1.
This chapter focuses entirely on the floresta-wire crate, so stay tuned!
Revisiting the UtreexoNode Type
The two fields of UtreexoNode are the NodeCommon<Chain> struct and the generic Context.
NodeCommon represents the core state and data required for node operations, independent of the context. It keeps the Chain backend, optional compact block filters, the mempool, the UtreexoNodeConfig and Network, peer connection data, networking configurations, and time-based events to enable effective node behavior and synchronization.
Filename: floresta-wire/src/p2p_wire/node.rs
// Path: floresta-wire/src/p2p_wire/node.rs
pub struct NodeCommon<Chain: ChainBackend> {
// 1. Core Blockchain and Transient Data
pub(crate) chain: Chain,
pub(crate) blocks: HashMap<BlockHash, InflightBlock>,
pub(crate) mempool: Arc<tokio::sync::Mutex<Mempool>>,
pub(crate) block_filters: Option<Arc<NetworkFilters<FlatFiltersStore>>>,
pub(crate) last_filter: BlockHash,
// 2. Peer Management
pub(crate) peer_id_count: u32,
pub(crate) peer_ids: Vec<u32>,
pub(crate) peers: HashMap<u32, LocalPeerView>,
pub(crate) peer_by_service: HashMap<ServiceFlags, Vec<u32>>,
pub(crate) max_banscore: u32,
pub(crate) address_man: AddressMan,
pub(crate) added_peers: Vec<AddedPeerInfo>,
// 3. Internal Communication
pub(crate) node_rx: UnboundedReceiver<NodeNotification>,
pub(crate) node_tx: UnboundedSender<NodeNotification>,
// 4. Networking Configuration
pub(crate) socks5: Option<Socks5StreamBuilder>,
pub(crate) fixed_peer: Option<LocalAddress>,
// 5. Time and Event Tracking
pub(crate) inflight: HashMap<InflightRequests, (u32, Instant)>,
pub(crate) inflight_user_requests:
HashMap<UserRequest, (u32, Instant, oneshot::Sender<NodeResponse>)>,
pub(crate) last_tip_update: Instant,
pub(crate) last_connection: Instant,
pub(crate) last_peer_db_dump: Instant,
pub(crate) last_block_request: u32,
pub(crate) last_get_address_request: Instant,
pub(crate) last_broadcast: Instant,
pub(crate) last_send_addresses: Instant,
pub(crate) block_sync_avg: FractionAvg,
pub(crate) last_feeler: Instant,
pub(crate) startup_time: Instant,
pub(crate) last_dns_seed_call: Instant,
// 6. Configuration and Metadata
pub(crate) config: UtreexoNodeConfig,
pub(crate) datadir: String,
pub(crate) network: Network,
pub(crate) kill_signal: Arc<tokio::sync::RwLock<bool>>,
}
pub struct UtreexoNode<Chain: ChainBackend, Context = RunningNode> {
pub(crate) common: NodeCommon<Chain>,
pub(crate) context: Context,
}On the other hand, the Context generic in UtreexoNode will allow the node to implement additional functionality and manage data specific to a particular context. This is explained in the next section.
Although the Context generic in the type definition is not constrained by any trait, in the UtreexoNode implementation block (from the same node.rs file), this generic is bound by both a NodeContext trait and the Default trait.
// Path: floresta-wire/src/p2p_wire/node.rs
impl<T, Chain> UtreexoNode<Chain, T>
where
T: 'static + Default + NodeContext,
Chain: ChainBackend + 'static,
WireError: From<Chain::Error>,
{
// ...In this implementation block, we also encounter a WireError, which serves as the unified error type for methods in UtreexoNode. It must implement the From trait to convert errors produced by the Chain backend via the BlockchainInterface trait (i.e., the Error associated type of the trait).
The
WireErrortype is defined in the p2p_wire/error.rs file and is the primary error type infloresta-wire, alongsidePeerError, located in p2p_wire/peer.rs.
How to Access Inner Fields
To avoid repetitively calling self.common.field_name to access the many inner NodeCommon fields, UtreexoNode implements the Deref and DerefMut traits. This means that we can access the NodeCommon fields as if they were fields of UtreexoNode.
// Path: floresta-wire/src/p2p_wire/node.rs
impl<Chain: ChainBackend, T> Deref for UtreexoNode<Chain, T> {
fn deref(&self) -> &Self::Target {
&self.common
}
type Target = NodeCommon<Chain>;
}
impl<T, Chain: ChainBackend> DerefMut for UtreexoNode<Chain, T> {
fn deref_mut(&mut self) -> &mut Self::Target {
&mut self.common
}
}However, the Context generic still needs to be accessed explicitly via self.context.
The Role of UtreexoNode
UtreexoNode acts as the central task managing critical events like:
- Receiving new blocks: Handling block announcements and integrating them into the blockchain.
- Managing peer connections and disconnections: Establishing, monitoring, and closing connections with other nodes.
- Updating peer addresses: Discovering, maintaining, and sharing network addresses of peers for efficient connectivity.
While the node orchestrates these high-level responsibilities, peer-specific tasks (e.g., handling pings and other peer messages) are delegated to the Floresta Peer type, ensuring a clean separation of concerns. The Peer component and its networking functionality will be explored in the next chapter.
In networking, a ping is a message sent between peers to check if they are online and responsive, often used to measure latency or maintain active connections.
In the next section we will understand the NodeContext trait and the different node Contexts that Floresta implements.
Node Contexts
A Bitcoin client goes through different phases during its lifetime, each with distinct responsibilities and requirements. To manage these phases, Floresta uses node contexts, which encapsulate the specific logic and behavior needed for each phase.
Instead of creating a monolithic UtreexoNode struct with all possible logic and conditional branches, the design separates shared functionality and phase-specific logic. The base UtreexoNode struct handles common features, while contexts, passed as generic parameters implementing the NodeContext trait, handle the specific behavior for each phase. This modular design simplifies the codebase and makes it more maintainable.
Default Floresta Contexts
The three node contexts in Floresta are:
-
ChainSelector: This context identifies the best proof-of-work (PoW) chain by downloading and evaluating multiple candidates. It quickly determines the chain with the highest PoW, as further client operations depend on this selection.
-
SyncNode: Responsible for downloading and verifying all blocks in the selected chain, this context ensures the chain's validity. Although it is computationally expensive and time-consuming, it guarantees that the chain is fully validated.
-
RunningNode: The primary context during normal operation, it starts operating after
ChainSelectorfinishes. This context processes new blocks (even ifSyncNodeis still running) and handles user requests.
RunningNode is the top-level context. When a UtreexoNode is first created, it will internally switch to the other contexts as needed, and then return to RunningNode. In practice, this makes RunningNode the default context used by florestad to run the node.
The NodeContext Trait
The following is the NodeContext trait definition, which holds many useful node constants and provides one method. Click see more in the snippet if you would like to see all the comments for each const.
Filename: p2p_wire/node_context.rs
// Path: floresta-wire/src/p2p_wire/node_context.rs
use bitcoin::p2p::ServiceFlags;
pub trait NodeContext {
/// How long we wait for a peer to respond to our request
const REQUEST_TIMEOUT: u64;
/// Max number of simultaneous connections we initiates we are willing to hold
const MAX_OUTGOING_PEERS: usize = 10;
/// We ask for peers every ASK_FOR_PEERS_INTERVAL seconds
const ASK_FOR_PEERS_INTERVAL: u64 = 60 * 60; // One hour
/// Save our database of peers every PEER_DB_DUMP_INTERVAL seconds
const PEER_DB_DUMP_INTERVAL: u64 = 30; // 30 seconds
/// Attempt to open a new connection (if needed) every TRY_NEW_CONNECTION seconds
const TRY_NEW_CONNECTION: u64 = 10; // 10 seconds
/// If ASSUME_STALE seconds passed since our last tip update, treat it as stale
const ASSUME_STALE: u64 = 15 * 60; // 15 minutes
/// While on IBD, if we've been without blocks for this long, ask for headers again
const IBD_REQUEST_BLOCKS_AGAIN: u64 = 30; // 30 seconds
/// How often we broadcast transactions
const BROADCAST_DELAY: u64 = 30; // 30 seconds
/// Max number of simultaneous inflight requests we allow
const MAX_INFLIGHT_REQUESTS: usize = 1_000;
/// Interval at which we open new feeler connections
const FEELER_INTERVAL: u64 = 30; // 30 seconds
/// Interval at which we rearrange our addresses
const ADDRESS_REARRANGE_INTERVAL: u64 = 60 * 60; // 1 hour
/// How long we ban a peer for
const BAN_TIME: u64 = 60 * 60 * 24;
/// How often we check if we haven't missed a block
const BLOCK_CHECK_INTERVAL: u64 = 60 * 5; // 5 minutes
/// How often we send our addresses to our peers
const SEND_ADDRESSES_INTERVAL: u64 = 60 * 60; // 1 hour
/// How long should we wait for a peer to respond our connection request
const CONNECTION_TIMEOUT: u64 = 30; // 30 seconds
/// How many blocks we can ask in the same request
const BLOCKS_PER_GETDATA: usize = 5;
/// How many concurrent GETDATA packages we can send at the same time
const MAX_CONCURRENT_GETDATA: usize = 10;
fn get_required_services(&self) -> ServiceFlags {
ServiceFlags::NETWORK
}
}
pub(crate) type PeerId = u32;The get_required_services implementation defaults to returning ServiceFlags::NETWORK, meaning the node is capable of serving the complete blockchain to peers on the network. This is a placeholder implementation, and as we’ll see, each context will provide its own ServiceFlags based on its role. Similarly, the constants can be customized when implementing NodeContext for a specific type.
bitcoin::p2p::ServiceFlagsis a fundamental type that represents the various services that nodes in the network can offer. Floresta extends this functionality by defining two additional service flags infloresta-common, which can be convertedintotheServiceFlagstype.// Path: floresta-common/src/lib.rs /// Non-standard service flags that aren't in rust-bitcoin yet pub mod service_flags { /// This peer supports UTREEXO messages pub const UTREEXO: u64 = 1 << 24; /// This peer supports UTREEXO filter messages pub const UTREEXO_FILTER: u64 = 1 << 25; }
Finally, we find the PeerId type alias that will be used to give each peer a specific identifier. This is all the code in node_context.rs.
Implementation Example
When we implement NodeContext for any meaningful type, we also implement the context-specific methods for UtreexoNode. Let's suppose we have a MyContext type:
// Example implementation for MyContext
impl NodeContext for MyContext {
fn get_required_services(&self) -> bitcoin::p2p::ServiceFlags {
// The node under MyContext can serve the whole blockchain as well
// as segregated witness (SegWit) data to other peers
ServiceFlags::WITNESS | ServiceFlags::NETWORK
}
const REQUEST_TIMEOUT: u64 = 10 * 60; // 10 minutes
}
// The following `impl` block is only for `UtreexoNode`s that use MyContext
impl<Chain> UtreexoNode<MyContext, Chain>
where
WireError: From<<Chain as BlockchainInterface>::Error>,
Chain: BlockchainInterface + UpdatableChainstate + 'static,
{
// Methods for UtreexoNode in MyContext
}Since UtreexoNode<RunningNode, _>, UtreexoNode<SyncNode, _>, and UtreexoNode<ChainSelector, _> are all entirely different types (because Rust considers each generic parameter combination a separate type), we cannot mistakenly use methods that are not intended for a specific context.
The only shared functionality is that which is implemented generically for T: NodeContext, which all three contexts satisfy, located in p2p_wire/node.rs (as we have seen in the previous section).
In the next sections within this chapter we will see some of these shared functions and methods implementations.
UtreexoNode Config and Builder
In this section and the next ones within this chapter, we are going to understand some methods implemented generically for UtreexoNode, that is, methods implemented for UtreexoNode under T: NodeContext rather than a specific context type.
While ChainSelector, SyncNode, and RunningNode provide impl blocks for UtreexoNode, those methods can only be used in a single context. Here, we will explore the functionality shared across all contexts.
UtreexoNode Builder
Let's start with the builder function, taking a UtreexoNodeConfig, the Chain backend, a mempool type, optional compact block filters from the floresta-compact-filters crate, a kill signal to stop the node, and the address manager backend (that we will see later in this chapter).
// Path: floresta-wire/src/p2p_wire/node.rs
impl<T, Chain> UtreexoNode<Chain, T>
where
T: 'static + Default + NodeContext,
Chain: ChainBackend + 'static,
WireError: From<Chain::Error>,
{
pub fn new(
config: UtreexoNodeConfig,
chain: Chain,
mempool: Arc<Mutex<Mempool>>,
block_filters: Option<Arc<NetworkFilters<FlatFiltersStore>>>,
kill_signal: Arc<tokio::sync::RwLock<bool>>,
address_man: AddressMan,
) -> Result<Self, WireError> {
let (node_tx, node_rx) = unbounded_channel();
let socks5 = config.proxy.map(Socks5StreamBuilder::new);
let fixed_peer = config
.fixed_peer
.as_ref()
.map(|address| Self::resolve_connect_host(address, Self::get_port(config.network)))
.transpose()?;
Ok(UtreexoNode {
common: NodeCommon {
// Initialization of many fields :P
last_dns_seed_call: Instant::now(),
startup_time: Instant::now(),
block_sync_avg: FractionAvg::new(0, 0),
last_filter: chain.get_block_hash(0).unwrap(),
block_filters,
inflight: HashMap::new(),
inflight_user_requests: HashMap::new(),
peer_id_count: 0,
peers: HashMap::new(),
last_block_request: chain.get_validation_index().expect("Invalid chain"),
chain,
peer_ids: Vec::new(),
peer_by_service: HashMap::new(),
mempool,
network: config.network,
node_rx,
node_tx,
address_man,
last_tip_update: Instant::now(),
last_connection: Instant::now(),
last_peer_db_dump: Instant::now(),
last_broadcast: Instant::now(),
last_feeler: Instant::now(),
blocks: HashMap::new(),
last_get_address_request: Instant::now(),
last_send_addresses: Instant::now(),
datadir: config.datadir.clone(),
max_banscore: config.max_banscore,
socks5,
fixed_peer,
config,
kill_signal,
added_peers: Vec::new(),
},
context: T::default(),
})
}
// ...The UtreexoNodeConfig type outlines all the customizable options for running a UtreexoNode. It specifies essential settings like the network, connection preferences, and resource management options. It also has a UtreexoNodeConfig::default implementation. This type is better explained below.
Then, the Mempool type that we see in the signature is a very simple mempool implementation for broadcasting transactions to the network.
The first line creates an unbounded multi-producer, single-consumer (mpsc) channel, allowing multiple tasks in the UtreexoNode to send messages (via the sender node_tx) to a central task that processes them (via the receiver node_rx). If you are not familiar with channels, there's a section from the Rust book that covers them. Here, we use tokio channels instead of Rust's standard library channels.
The
unbounded_channelhas no backpressure, meaning producers can keep sending messages without being slowed down, even if the receiver is behind. While this is convenient, it comes with the risk of excessive memory use if messages accumulate faster than they are processed.
The second line sets up a SOCKS5 proxy connection if a proxy address (config.proxy) is provided. SOCKS5 is a protocol that routes network traffic through a proxy server, useful for privacy or bypassing network restrictions. The Socks5StreamBuilder is a wrapper for core::net::SocketAddr, implemented in p2p_wire/socks.rs. If no proxy is configured, the node will connect directly to the network.
// Path: floresta-wire/src/p2p_wire/socks.rs
impl Socks5StreamBuilder {
pub fn new(address: SocketAddr) -> Self {
Self { address }
}
// ...Thirdly, we take the config.fixed_peer, which is an Option<String>, and convert it into an Option<LocalAddress> by using the UtreexoNode::resolve_connect_host function. LocalAddress is the local representation of a peer address in Floresta, which we will explore in the Address Manager section.
Finally, the function returns the UtreexoNode with all the NodeCommon fields initialized and the default value of the passed NodeContext.
UtreexoNodeConfig
Let's now check what are the customizable options for the node, that is, the UtreexoNodeConfig struct.
It starts with the network field (i.e. Bitcoin, Testnet, Regtest or Signet). Next we find the key options to enable pow_fraud_proofs for a very fast node sync, which we learned about in the PoW Fraud Proofs Sync section from last chapter, and compact_filters for lightweight blockchain rescans.
A fixed peer can be specified via fixed_peer, and settings like max_banscore, max_outbound, and max_inflight allow fine-tuning of peer management, connection limits, and parallel requests.
Filename: p2p_wire/mod.rs
// Path: floresta-wire/src/p2p_wire/mod.rs
pub struct UtreexoNodeConfig {
/// The blockchain we are in, defaults to Bitcoin. Possible values are Bitcoin,
/// Testnet, Regtest and Signet.
pub network: Network,
/// Whether to use PoW fraud proofs. Defaults to false.
///
/// PoW fraud proof is a mechanism to skip the verification of the whole blockchain,
/// but while also giving a better security than simple SPV.
pub pow_fraud_proofs: bool,
/// Whether to use compact filters. Defaults to false.
///
/// Compact filters are useful to rescan the blockchain for a specific address, without
/// needing to download the whole chain. It will download ~1GB of filters, and then
/// download the blocks that match the filters.
pub compact_filters: bool,
/// Fixed peers to connect to. Defaults to None.
///
/// If you want to connect to a specific peer, you can set this to a string with the
/// format `ip:port`. For example, `localhost:8333`.
pub fixed_peer: Option<String>,
/// If a peer misbehaves, we increase its ban score. If the ban score reaches this value,
/// we disconnect from the peer. Defaults to 100.
pub max_banscore: u32,
/// Maximum number of outbound connections. Defaults to 8.
pub max_outbound: u32,
/// Maximum number of inflight requests. Defaults to 10.
///
/// More inflight requests means more memory usage, but also more parallelism.
pub max_inflight: u32,
// ...
/// Data directory for the node. Defaults to `.floresta-node`.
pub datadir: String,
/// A SOCKS5 proxy to use. Defaults to None.
pub proxy: Option<SocketAddr>,
/// If enabled, the node will assume that the provided Utreexo state is valid, and will
/// start running from there
pub assume_utreexo: Option<AssumeUtreexoValue>,
/// If we assumeutreexo or pow_fraud_proof, we can skip the IBD and make our node usable
/// faster, with the tradeoff of security. If this is enabled, we will still download the
/// blocks in the background, and verify the final Utreexo state. So, the worse case scenario
/// is that we are vulnerable to a fraud proof attack for a few hours, but we can spot it
/// and react in a couple of hours at most, so the attack window is very small.
pub backfill: bool,
/// If we are using network-provided block filters, we may not need to download the whole
/// chain of filters, as our wallets may not have been created at the beginning of the chain.
/// With this option, we can make a rough estimate of the block height we need to start
/// and only download the filters from that height.
///
/// If the value is negative, it's relative to the current tip. For example, if the current
/// tip is at height 1000, and we set this value to -100, we will start downloading filters
/// from height 900.
pub filter_start_height: Option<i32>,
/// The user agent that we will advertise to our peers. Defaults to `floresta:<version>`.
pub user_agent: String,
/// Whether to allow fallback to v1 transport if v2 connection fails.
/// Defaults to true.
pub allow_v1_fallback: bool,
/// Whether to disable DNS seeds. Defaults to false.
pub disable_dns_seeds: bool,
}
impl Default for UtreexoNodeConfig {
fn default() -> Self {
UtreexoNodeConfig {
disable_dns_seeds: false,
network: Network::Bitcoin,
pow_fraud_proofs: false,
compact_filters: false,
fixed_peer: None,
max_banscore: 100,
max_outbound: 8,
max_inflight: 10,
datadir: ".floresta-node".to_string(),
proxy: None,
backfill: false,
assume_utreexo: None,
filter_start_height: None,
user_agent: format!("floresta:{}", env!("CARGO_PKG_VERSION")),
allow_v1_fallback: true,
}
}
}Additional configurations include datadir for specifying the node's data directory and an optional proxy for connecting through a SOCKS5 proxy. Then we see the assume_utreexo option, which we also explained in the Trusted UTXO Set Snapshots section from last chapter.
// Path: floresta-wire/src/p2p_wire/mod.rs
pub struct UtreexoNodeConfig {
/// The blockchain we are in, defaults to Bitcoin. Possible values are Bitcoin,
/// Testnet, Regtest and Signet.
pub network: Network,
/// Whether to use PoW fraud proofs. Defaults to false.
///
/// PoW fraud proof is a mechanism to skip the verification of the whole blockchain,
/// but while also giving a better security than simple SPV.
pub pow_fraud_proofs: bool,
/// Whether to use compact filters. Defaults to false.
///
/// Compact filters are useful to rescan the blockchain for a specific address, without
/// needing to download the whole chain. It will download ~1GB of filters, and then
/// download the blocks that match the filters.
pub compact_filters: bool,
/// Fixed peers to connect to. Defaults to None.
///
/// If you want to connect to a specific peer, you can set this to a string with the
/// format `ip:port`. For example, `localhost:8333`.
pub fixed_peer: Option<String>,
/// If a peer misbehaves, we increase its ban score. If the ban score reaches this value,
/// we disconnect from the peer. Defaults to 100.
pub max_banscore: u32,
/// Maximum number of outbound connections. Defaults to 8.
pub max_outbound: u32,
/// Maximum number of inflight requests. Defaults to 10.
///
/// More inflight requests means more memory usage, but also more parallelism.
pub max_inflight: u32,
/// Data directory for the node. Defaults to `.floresta-node`.
// ...
pub datadir: String,
/// A SOCKS5 proxy to use. Defaults to None.
pub proxy: Option<SocketAddr>,
/// If enabled, the node will assume that the provided Utreexo state is valid, and will
/// start running from there
pub assume_utreexo: Option<AssumeUtreexoValue>,
/// If we assumeutreexo or pow_fraud_proof, we can skip the IBD and make our node usable
/// faster, with the tradeoff of security. If this is enabled, we will still download the
/// blocks in the background, and verify the final Utreexo state. So, the worse case scenario
/// is that we are vulnerable to a fraud proof attack for a few hours, but we can spot it
/// and react in a couple of hours at most, so the attack window is very small.
pub backfill: bool,
/// If we are using network-provided block filters, we may not need to download the whole
/// chain of filters, as our wallets may not have been created at the beginning of the chain.
/// With this option, we can make a rough estimate of the block height we need to start
/// and only download the filters from that height.
///
/// If the value is negative, it's relative to the current tip. For example, if the current
/// tip is at height 1000, and we set this value to -100, we will start downloading filters
/// from height 900.
pub filter_start_height: Option<i32>,
/// The user agent that we will advertise to our peers. Defaults to `floresta:<version>`.
pub user_agent: String,
/// Whether to allow fallback to v1 transport if v2 connection fails.
/// Defaults to true.
pub allow_v1_fallback: bool,
/// Whether to disable DNS seeds. Defaults to false.
pub disable_dns_seeds: bool,
}
impl Default for UtreexoNodeConfig {
fn default() -> Self {
UtreexoNodeConfig {
disable_dns_seeds: false,
network: Network::Bitcoin,
pow_fraud_proofs: false,
compact_filters: false,
fixed_peer: None,
max_banscore: 100,
max_outbound: 8,
max_inflight: 10,
datadir: ".floresta-node".to_string(),
proxy: None,
backfill: false,
assume_utreexo: None,
filter_start_height: None,
user_agent: format!("floresta:{}", env!("CARGO_PKG_VERSION")),
allow_v1_fallback: true,
}
}
}If one of pow_fraud_proofs or assume_utreexo is set, the backfill option enables background and full validation of the chain, which is recommended for security since the node skipped the IBD.
For block filters, filter_start_height helps optimize downloads by starting from a specific height rather than the chain’s beginning. In relation to networking, user_agent allows nodes to customize their identifier when advertising to peers. Also, allow_v1_fallback is used for specifying if our node should use the version 1 P2P transport protocol as a fallback if we encounter a problem when connecting via the version 2 transport.
Lastly, if disable_dns_seeds is set, our node will not perform any DNS seed lookups to find peers. Instead, it will use hardcoded peer addresses, found at the floresta-wire seeds subdirectory.
This flexible configuration ensures adaptability for various use cases and security levels, from development to production.
Opening Connections
In this section we are finally going to understand how Floresta connects to peers. The highest-level method for opening connections is maybe_open_connection, which will redirect us to other lower-level functionality. Remember that these methods are context-independent.
When to Open Connections
The maybe_open_connection method determines whether the node should establish a new connection to a peer and, if so, calls create_connection.
// Path: floresta-wire/src/p2p_wire/node.rs
pub(crate) fn maybe_open_connection(
&mut self,
required_service: ServiceFlags,
) -> Result<(), WireError> {
// If the user passes in a `--connect` cli argument, we only connect with
// that particular peer.
if self.fixed_peer.is_some() && !self.peers.is_empty() {
return Ok(());
}
// If we've tried getting some connections, but the addresses we have are not
// working. Try getting some more addresses from DNS
self.maybe_ask_for_dns_peers();
let needs_utreexo = required_service.has(service_flags::UTREEXO.into());
self.maybe_use_hadcoded_addresses(needs_utreexo);
// Try to connect with manually added peers
self.maybe_open_connection_with_added_peers()?;
let connection_kind = ConnectionKind::Regular(required_service);
if self.peers.len() < T::MAX_OUTGOING_PEERS {
self.create_connection(connection_kind)?;
}
Ok(())
}If the user has specified a fixed peer via the --connect command-line argument (self.fixed_peer.is_some()) and there are already connected peers (!self.peers.is_empty()), the method does nothing and exits early. This is because we have already connected to the fixed peer.
Also, if the number of peers is below the maximum allowed (self.peers.len() < T::MAX_OUTGOING_PEERS), it calls the create_connection method to establish a new 'regular' connection to a peer.
The ConnectionKind struct that create_connection takes as argument is explained below.
Connection Kinds
// Path: floresta-wire/src/p2p_wire/node.rs
pub enum ConnectionKind {
Feeler,
// bitcoin::p2p::ServiceFlags
Regular(ServiceFlags),
Extra,
}Feeler Connections
Feeler connections are temporary probes used to verify if a peer is still active, regardless of its supported services. These lightweight tests help maintain an up-to-date and reliable pool of peers, ensuring the node can quickly establish connections when needed.
Regular Connections
Regular connections are the backbone of a node's peer-to-peer communication. These connections are established with trusted peers or those that meet specific service criteria (e.g., support for Utreexo or compact filters). Regular connections are long-lived and handle the bulk of the node's operations, such as exchanging blocks, headers, transactions, and keeping the node in sync.
Extra Connections
Extra connections extend the node’s reach by connecting to additional peers for specialized tasks, such as compact filter requests or fetching Utreexo proofs. These are temporary and created only when extra resources are required.
Create Connection
create_connection takes the required services for the connection kind, gets a peer address (prioritizing the fixed peer if specified), and ensures the peer isn’t already connected.
If no fixed peer is specified, we get a suitable peer address (or LocalAddress) for connection by calling self.address_man.get_address_to_connect. This method takes the required services and a boolean indicating whether a feeler connection is desired. We will explore this method in the next section.
// Path: floresta-wire/src/p2p_wire/node.rs
pub(crate) fn create_connection(&mut self, kind: ConnectionKind) -> Result<(), WireError> {
let required_services = match kind {
ConnectionKind::Regular(services) => services,
_ => ServiceFlags::NONE,
};
let address = self
.fixed_peer
.as_ref()
.map(|addr| (0, addr.clone()))
.or_else(|| {
self.address_man.get_address_to_connect(
required_services,
matches!(kind, ConnectionKind::Feeler),
)
});
let Some((peer_id, address)) = address else {
// No peers with the desired services are known, load hardcoded addresses
let net = self.network;
self.address_man.add_fixed_addresses(net);
return Err(WireError::NoAddressesAvailable);
};
debug!("attempting connection with address={address:?} kind={kind:?}",);
let now = SystemTime::now()
.duration_since(UNIX_EPOCH)
.unwrap()
.as_secs();
// Defaults to failed, if the connection is successful, we'll update the state
self.address_man
.update_set_state(peer_id, AddressState::Failed(now));
// Don't connect to the same peer twice
let is_connected = |(_, peer_addr): (_, &LocalPeerView)| {
peer_addr.address == address.get_net_address() && peer_addr.port == address.get_port()
};
if self.common.peers.iter().any(is_connected) {
return Err(WireError::PeerAlreadyExists(
address.get_net_address(),
address.get_port(),
));
}
// We allow V1 fallback only if the cli option was set, it's a --connect peer
// or if we are connecting to a utreexo peer, since utreexod doesn't support V2 yet.
let is_fixed = self.fixed_peer.is_some();
let allow_v1 = self.config.allow_v1_fallback
|| kind == ConnectionKind::Regular(UTREEXO.into())
|| is_fixed;
self.open_connection(kind, peer_id, address, allow_v1)?;
Ok(())
}Then we use the obtained LocalAddress and the peer identifier as arguments for open_connection, as well as the connection kind and whether we should fall back to the V1 P2P protocol if the V2 handshake fails.
Both the LocalAddress type and the get_address_to_connect method are implemented in the address manager module (p2p_wire/address_man.rs) that we will see in the next section.
Open Connection
Moving on to open_connection, we create a new unbounded_channel for sending requests to the Peer instance. Recall that the Peer component is in charge of actually connecting to the respective peer over the network.
Then, depending on the value of self.socks5 we will call UtreexoNode::open_proxy_connection or UtreexoNode::open_non_proxy_connection. Each one of these functions will create a Peer instance with the provided data and the channel receiver.
// Path: floresta-wire/src/p2p_wire/node.rs
pub(crate) fn open_connection(
&mut self,
kind: ConnectionKind,
peer_id: usize,
address: LocalAddress,
allow_v1_fallback: bool,
) -> Result<(), WireError> {
let (requests_tx, requests_rx) = unbounded_channel();
if let Some(ref proxy) = self.socks5 {
spawn(timeout(
Duration::from_secs(10),
Self::open_proxy_connection(
// Arguments omitted for brevity :P
proxy.address,
kind,
self.mempool.clone(),
self.network,
self.node_tx.clone(),
peer_id,
address.clone(),
requests_rx,
self.peer_id_count,
self.config.user_agent.clone(),
allow_v1_fallback,
),
));
} else {
spawn(timeout(
Duration::from_secs(10),
Self::open_non_proxy_connection(
// Arguments omitted for brevity :P
kind,
peer_id,
address.clone(),
requests_rx,
self.peer_id_count,
self.mempool.clone(),
self.network,
self.node_tx.clone(),
self.config.user_agent.clone(),
allow_v1_fallback,
),
));
}
let peer_count: u32 = self.peer_id_count;
self.inflight.insert(
InflightRequests::Connect(peer_count),
(peer_count, Instant::now()),
);
self.peers.insert(
peer_count,
LocalPeerView {
// Fields omitted for brevity :P
address: address.get_net_address(),
port: address.get_port(),
user_agent: "".to_string(),
state: PeerStatus::Awaiting,
channel: requests_tx,
services: ServiceFlags::NONE,
_last_message: Instant::now(),
kind,
address_id: peer_id as u32,
height: 0,
banscore: 0,
// Will be downgraded to V1 if the V2 handshake fails, and we allow fallback
transport_protocol: TransportProtocol::V2,
},
);
match kind {
ConnectionKind::Feeler => self.last_feeler = Instant::now(),
ConnectionKind::Regular(_) => self.last_connection = Instant::now(),
_ => {}
}
self.peer_id_count += 1;
Ok(())
}Last of all, we simply insert the new inflight request (via the InflightRequests type) to our tracker HashMap, as well as the new peer (via the LocalPeerView). Both types are also defined in p2p_wire/node.rs, along with UtreexoNode, NodeCommon, ConnectionKind, and a few other types.
Recap
In this section, we have learned how Floresta establishes peer-to-peer connections, starting with the maybe_open_connection method. This method initiates a connection if we aren't already connected to the optional fixed peer and either have fewer connections than Context::MAX_OUTGOING_PEERS or lack a peer offering utreexo services.
We explored the three connection types: Feeler (peer availability check), Regular (core communication), and Extra (specialized services). The create_connection method selects an appropriate peer address while preventing duplicate connections, and open_connection handles the network setup, either via a proxy or directly (internally creating a new Peer). Finally, we examined how new connections are tracked using inflight requests and a peer registry, both fields of NodeCommon.
Address Manager
Before diving into the details of P2P networking, let's understand the crucial address manager module.
In the last section, we saw that the create_connection method uses the self.address_man.get_address_to_connect method to obtain a suitable address for connection. This method belongs to the AddressMan struct (a field from NodeCommon), which is responsible for maintaining a record of known peer addresses and providing them to the node when needed.
Filename: p2p_wire/address_man.rs
// Path: floresta-wire/src/p2p_wire/address_man.rs
pub struct AddressMan {
addresses: HashMap<usize, LocalAddress>,
good_addresses: Vec<usize>,
good_peers_by_service: HashMap<ServiceFlags, Vec<usize>>,
peers_by_service: HashMap<ServiceFlags, Vec<usize>>,
}This struct is straightforward: it keeps known peer addresses in a HashMap (as LocalAddress), the indexes of good peers in the map, and associates peers with the services they support.
Local Address
We have also encountered the LocalAddress type a few times, which is implemented in this module. This type encapsulates all the information our node knows about each peer, effectively serving as our local representation of the peer's details.
// Path: floresta-wire/src/p2p_wire/address_man.rs
pub struct LocalAddress {
/// An actual address
address: AddrV2,
/// Last time we successfully connected to this peer, in secs, only relevant if state == State::Tried
last_connected: u64,
/// Our local state for this peer, as defined in AddressState
state: AddressState,
/// Network services announced by this peer
services: ServiceFlags,
/// Network port this peers listens to
port: u16,
/// Random id for this peer
pub id: usize,
}The actual address is stored in the form of an AddrV2 enum, which is implemented by the bitcoin crate. AddrV2 represents various network address types supported in Bitcoin's P2P protocol, as defined in BIP155.
Concretely,
AddrV2includes variants forIPv4,IPv6,Tor(v2 and v3),I2P,Cjdnsaddresses, and anUnknownvariant for unrecognized address types. This design allows the protocol to handle a diverse set of network addresses.
The LocalAddress also stores the last connection date or time, measured as seconds since the UNIX_EPOCH, an AddressState struct, the network services announced by the peer, the port that the peer listens to, and its identifier.
Below is the definition of AddressState, which tracks the current status and history of our interactions with this peer:
// Path: floresta-wire/src/p2p_wire/address_man.rs
pub enum AddressState {
/// We never tried this peer before, so we don't know what to expect. This variant
/// also applies to peers that we tried to connect, but failed, or we didn't connect
/// to for a long time.
NeverTried,
/// We tried this peer before, and had success at least once, so we know what to expect
Tried(u64),
/// This peer misbehaved and we banned them
Banned(u64),
/// We are connected to this peer right now
Connected,
/// We tried connecting, but failed
Failed(u64),
}Get Address to Connect
Let's finally inspect the get_address_to_connect method on the AddressMan, which we use to create connections.
This method selects a peer address for a new connection based on required services and whether the connection is a feeler. First of all, we will return None if the address manager doesn't have any peers. Otherwise:
- For feeler connections, it randomly picks an address, or returns
Noneif the peer isBannedor alreadyConnected. - For regular connections, it prioritizes peers supporting the required services or falls back to a random address. Peers in the
NeverTriedandTriedstates are considered valid,Connectedones are skipped, andBannedandFailedones are only accepted if enough time has passed. If no suitable address is found, it returnsNone.
// Path: floresta-wire/src/p2p_wire/address_man.rs
/// Returns a new random address to open a new connection, we try to get addresses with
/// a set of features supported for our peers
pub fn get_address_to_connect(
&mut self,
required_service: ServiceFlags,
feeler: bool,
) -> Option<(usize, LocalAddress)> {
if self.addresses.is_empty() {
return None;
}
// Feeler connection are used to test if a peer is still alive, we don't care about
// the features it supports or even if it's a valid peer. The only thing we care about
// is that we haven't banned it.
if feeler {
let idx = rand::random::<usize>() % self.addresses.len();
let peer = self.addresses.keys().nth(idx)?;
let address = self.addresses.get(peer)?.to_owned();
if matches!(address.state, AddressState::Banned(_))
| matches!(address.state, AddressState::Connected)
{
return None;
}
return Some((*peer, address));
};
for _ in 0..10 {
let (id, peer) = self
.get_address_by_service(required_service)
.or_else(|| self.get_random_address(required_service))?;
match peer.state {
AddressState::NeverTried | AddressState::Tried(_) => {
return Some((id, peer));
}
AddressState::Connected => {
continue;
}
AddressState::Banned(when) | AddressState::Failed(when) => {
let now = SystemTime::now()
.duration_since(UNIX_EPOCH)
.unwrap()
.as_secs();
if when + RETRY_TIME < now {
return Some((id, peer));
}
if let Some(peers) = self.good_peers_by_service.get_mut(&required_service) {
peers.retain(|&x| x != id)
}
self.good_addresses.retain(|&x| x != id);
}
}
}
None
}Dump Peers
Another key functionality implemented in this module is the ability to write the current peer data to a peers.json file, enabling the node to resume peer connections after a restart without repeating the initial peer discovery process.
To save each LocalAddress we use a slightly modified type called DiskLocalAddress, similar to how we used the DiskBlockHeader type to persist BlockHeaders.
// Path: floresta-wire/src/p2p_wire/address_man.rs
pub fn dump_peers(&self, datadir: &str) -> std::io::Result<()> {
let peers: Vec<_> = self
.addresses
.values()
.cloned()
.map(Into::<DiskLocalAddress>::into)
.collect::<Vec<_>>();
let peers = serde_json::to_string(&peers);
if let Ok(peers) = peers {
std::fs::write(datadir.to_owned() + "/peers.json", peers)?;
}
Ok(())
}Similarly, there's a dump_utreexo_peers method for persisting the utreexo peers into an anchors.json file. Peers that support utreexo are very valuable for our node; we need their utreexo proofs for validating blocks, and they are rare in the network.
// Path: floresta-wire/src/p2p_wire/address_man.rs
/// Dumps the connected utreexo peers to a file on dir `datadir/anchors.json` in json format `
/// inputs are the directory to save the file and the list of ids of the connected utreexo peers
pub fn dump_utreexo_peers(&self, datadir: &str, peers_id: &[usize]) -> std::io::Result<()> {
// ...
let addresses: Vec<DiskLocalAddress> = peers_id
.iter()
.filter_map(|id| Some(self.addresses.get(id)?.to_owned().into()))
.collect();
let addresses: Result<String, serde_json::Error> = serde_json::to_string(&addresses);
if let Ok(addresses) = addresses {
std::fs::write(datadir.to_owned() + "/anchors.json", addresses)?;
}
Ok(())
}Great! This concludes the chapter. In the next chapter, we will dive into P2P communication and networking, focusing on the Peer type.
Peer-to-Peer Networking
In the previous chapter, we learned how UtreexoNode opens connections, although we didn't dive into the low-level networking details. We mentioned that each peer connection is handled by the Peer type, keeping the peer networking logic separate from UtreexoNode.
In this chapter, we will explore the details of Peer operations, beginning with the low-level logic for opening connections (that is, the Peer creation).
Peer Creation
Recall that in the open_connection method on UtreexoNode we call either UtreexoNode::open_proxy_connection or UtreexoNode::open_non_proxy_connection, depending on the self.socks5 proxy option. It's within these two functions that the Peer is created. Let's first learn how the direct TCP connection is opened!
The open_non_proxy_connection function will first retrieve the peer's network address and port from the provided LocalAddress. Then it will attempt to establish a TCP connection using transport::connect (implemented in the transport module, which handles both the v1 and v2 transport protocols).
If successful, we get the transport reader and writer, which are of type ReadTransport and WriteTransport, defined in p2p_wire/transport.rs. Respectively, these two types wrap a tokio ReadHalf<TcpStream>, for receiving data, and a WriteHalf<TcpStream>, for sending data to the peer. We also get the transport protocol enum, with two possible variants, V1 or V2.
It then sets up an 'actor', that is, an independent component that reads incoming messages and communicates them to the 'actor receiver'. The actor is effectively a transport reader wrapper.
// Path: floresta-wire/src/p2p_wire/node.rs
pub(crate) async fn open_non_proxy_connection(
kind: ConnectionKind,
peer_id: usize,
address: LocalAddress,
requests_rx: UnboundedReceiver<NodeRequest>,
peer_id_count: u32,
mempool: Arc<Mutex<Mempool>>,
network: Network,
node_tx: UnboundedSender<NodeNotification>,
user_agent: String,
allow_v1_fallback: bool,
) -> Result<(), WireError> {
let address = (address.get_net_address(), address.get_port());
let (transport_reader, transport_writer, transport_protocol) =
transport::connect(address, network, allow_v1_fallback).await?;
let (cancellation_sender, cancellation_receiver) = oneshot::channel();
let (actor_receiver, actor) = create_actors(transport_reader);
tokio::spawn(async move {
tokio::select! {
_ = cancellation_receiver => {}
_ = actor.run() => {}
}
});
// Use create_peer function instead of manually creating the peer
Peer::<WriteHalf>::create_peer(
peer_id_count,
mempool,
node_tx.clone(),
requests_rx,
peer_id,
kind,
actor_receiver,
transport_writer,
user_agent,
cancellation_sender,
transport_protocol,
);
Ok(())
}This actor is obtained via the create_actors function, implemented in p2p_wire/peer.rs, and is of type MessageActor. The actor is spawned as a separate asynchronous task, ensuring it runs independently to handle incoming data.
Very importantly, the actor for a peer must be closed when the connection finalizes, and this is why we have an additional one-time-use channel, used by the Peer type to send a cancellation signal (essentially saying "the peer connection is closed, so there’s nothing left to listen to"). The tokio::select macro ensures that the async actor task is dropped whenever a cancellation signal is received from Peer.
Finally, the Peer instance is created using the Peer::create_peer function. The communication channels (internal and over the P2P network) that the Peer uses are:
- The node sender (
node_tx): to send messages toUtreexoNode. - The requests receiver (
requests_rx): to receive requests fromUtreexoNodethat will be sent to the peer. - The
actor_receiver: to receive peer messages. - The
transport_writer: to send messages to the peer. - The
cancellation_sender: to close the reader actor task.
By the end of this function, a fully initialized Peer is ready to manage communication with the connected peer via TCP (writing side) and via MessageActor (reading side), as well as communicating with UtreexoNode.
Proxy Connection
The open_proxy_connection is pretty much the same, except we get the transport reader and writer from the proxy connection instead, handled by transport::connect_proxy.
// Path: floresta-wire/src/p2p_wire/node.rs
pub(crate) async fn open_proxy_connection(
proxy: SocketAddr,
// ...
kind: ConnectionKind,
mempool: Arc<Mutex<Mempool>>,
network: Network,
node_tx: UnboundedSender<NodeNotification>,
peer_id: usize,
address: LocalAddress,
requests_rx: UnboundedReceiver<NodeRequest>,
peer_id_count: u32,
user_agent: String,
allow_v1_fallback: bool,
) -> Result<(), WireError> {
let (transport_reader, transport_writer, transport_protocol) =
transport::connect_proxy(proxy, address, network, allow_v1_fallback).await?;
let (cancellation_sender, cancellation_receiver) = oneshot::channel();
let (actor_receiver, actor) = create_actors(transport_reader);
tokio::spawn(async move {
tokio::select! {
_ = cancellation_receiver => {}
_ = actor.run() => {}
}
});
Peer::<WriteHalf>::create_peer(
// Same as before
peer_id_count,
mempool,
node_tx,
requests_rx,
peer_id,
kind,
actor_receiver,
transport_writer,
user_agent,
cancellation_sender,
transport_protocol,
);
Ok(())
}Recap of Channels
Let's do a brief recap of the channels we have opened for internal node message passing:
-
Node Channel (
Peer->UtreexoNode)Peersends vianode_txUtreexoNodereceives viaNodeCommon.node_rx
-
Requests Channel (
UtreexoNode->Peer)UtreexoNodesends via eachLocalPeerView.channel, stored inNodeCommon.peersPeerreceives via itsrequests_rx
-
Message Actor Channel (
MessageActor->Peer)MessageActorsends viaactor_senderPeerreceives viaactor_receiver
-
Cancellation Signal Channel (
Peer->UtreexoNode)Peersends the signal viacancellation_senderat the end of the connectionUtreexoNodereceives it viacancellation_receiver
UtreexoNode sends requests via the Request Channel to the Peer component (which then forwards them to the peer via TCP), Peer receives the result or other peer messages via the Actor Channel, and then it notifies UtreexoNode via the Node Channel. When the peer connection is closed, Peer uses the Cancellation Signal Channel to allow the TCP actor listening to the peer to be closed as well.
Next, we'll explore how messages are read and sent in the P2P network!
Reading and Writing Messages
Let's first learn about the MessageActor we created just before instantiating the Peer type, tasked with reading messages from the corresponding peer.
TCP Message Actor
The MessageActor type is a simple struct that wraps the transport reader and communicates to the Peer via an unbound channel.
Filename: p2p_wire/peer.rs
// Path: floresta-wire/src/p2p_wire/peer.rs
pub struct MessageActor<R: AsyncRead + Unpin + Send> {
pub transport: ReadTransport<R>,
pub sender: UnboundedSender<ReaderMessage>,
}// Path: floresta-wire/src/p2p_wire/peer.rs
pub fn create_actors<R: AsyncRead + Unpin + Send>(
transport: ReadTransport<R>,
) -> (UnboundedReceiver<ReaderMessage>, MessageActor<R>) {
// Open an unbound channel to communicate read peer messages
let (actor_sender, actor_receiver) = unbounded_channel();
// Initialize the actor with the `actor_sender` and the transport reader
let actor = MessageActor {
transport,
sender: actor_sender,
};
// Return the `actor_receiver` (to receive P2P messages from the actor), and the actor
(actor_receiver, actor)
}This MessageActor implements a run method, which independently handles all incoming messages from the corresponding peer, and sends them to the Peer type.
Note that the messages of the channel between MessageActor and Peer are of type ReaderMessage. Let's briefly inspect this enum, which is also defined in peer.rs.
// Path: floresta-wire/src/p2p_wire/peer.rs
pub enum ReaderMessage {
Message(NetworkMessage),
Error(PeerError),
}NetworkMessageis a type from thebitcoincrate, used for all P2P messages.PeerErroris the unified error type for thePeerstruct (similar to howWireErroris the error type forUtreexoNode).
Reading Messages
The run method simply invokes the inner method, and if it fails we notify the error to the Peer. The inner method is responsible for continuously reading messages from the transport via read_message and sending them to the Peer.
// Path: floresta-wire/src/p2p_wire/peer.rs
async fn inner(&mut self) -> std::result::Result<(), PeerError> {
loop {
let msg = self.transport.read_message().await?;
self.sender.send(ReaderMessage::Message(msg))?;
}
}
pub async fn run(mut self) -> Result<()> {
if let Err(err) = self.inner().await {
self.sender.send(ReaderMessage::Error(err))?;
}
Ok(())
}The read_message method, implemented in transport.rs, will actually read all the data from the peer, using either the v1 or v2 transport protocols.
Writing Messages
In order to write messages via the transport, we use the following write method on Peer:
// Path: floresta-wire/src/p2p_wire/peer.rs
pub async fn write(&mut self, msg: NetworkMessage) -> Result<()> {
debug!("Writing {} to peer {}", msg.command(), self.id);
self.writer.write_message(msg).await?;
Ok(())
}Once again, here we delegate on a write_message method on the transport writer component. This method serializes the data and sends it via the respective transport protocol.
And that's all about how we read and write P2P messages! Next, we'll explore a few Peer methods and how it handles network messages.
Handling Peer Messages
As we can see below, the only thing the Peer::create_peer method does is initializing the Peer and running its read_loop method.
// Path: floresta-wire/src/p2p_wire/peer.rs
pub fn create_peer<W: AsyncWrite + Unpin + Send + Sync + 'static>(
// ...
id: u32,
mempool: Arc<Mutex<Mempool>>,
node_tx: UnboundedSender<NodeNotification>,
node_requests: UnboundedReceiver<NodeRequest>,
address_id: usize,
kind: ConnectionKind,
actor_receiver: UnboundedReceiver<ReaderMessage>,
writer: WriteTransport<W>,
our_user_agent: String,
cancellation_sender: tokio::sync::oneshot::Sender<()>,
transport_protocol: TransportProtocol,
) {
let peer = Peer {
// Initializing the many Peer fields :P
address_id,
blocks_only: false,
current_best_block: -1,
id,
mempool,
last_ping: None,
last_message: Instant::now(),
node_tx,
services: ServiceFlags::NONE,
messages: 0,
start_time: Instant::now(),
user_agent: "".into(),
state: State::None,
send_headers: false,
node_requests,
kind,
wants_addrv2: false,
shutdown: false,
actor_receiver, // Add the receiver for messages from TcpStreamActor
writer,
our_user_agent,
cancellation_sender,
transport_protocol,
};
spawn(peer.read_loop());
}This read_loop method will in turn call a peer_loop_inner method:
// Path: floresta-wire/src/p2p_wire/peer.rs
pub async fn read_loop(mut self) -> Result<()> {
let err = self.peer_loop_inner().await;
// Check any errors returned by the loop, shutdown the stream writer
// and send cancellation signal to close the stream reader (actor task)
// ...
if err.is_err() {
debug!("Peer {} connection loop closed: {err:?}", self.id);
}
self.send_to_node(PeerMessages::Disconnected(self.address_id));
// force the stream to shutdown to prevent leaking resources
if let Err(shutdown_err) = self.writer.shutdown().await {
debug!(
"Failed to shutdown writer for Peer {}: {shutdown_err:?}",
self.id
);
}
if let Err(cancellation_err) = self.cancellation_sender.send(()) {
debug!(
"Failed to propagate cancellation signal for Peer {}: {cancellation_err:?}",
self.id
);
}
if let Err(err) = err {
debug!("Peer {} connection loop closed: {err:?}", self.id);
}
Ok(())
}The Peer Loop
The peer_loop_inner method is the main loop execution that handles all communication between the Peer component, the actual peer over the network, and the UtreexoNode. It sends P2P messages to the peer, processes requests from the node, and manages responses from the peer.
- Initial Handshake and Main Loop: At the start, the method sends a version message to the peer using
peer_utils::build_version_message, which initiates the handshake. Then the method enters an asynchronous loop where it handles node requests, peer messages, and ensures the peer connection remains healthy.
// Path: floresta-wire/src/p2p_wire/peer.rs
async fn peer_loop_inner(&mut self) -> Result<()> {
// send a version
let version = peer_utils::build_version_message(self.our_user_agent.clone());
self.write(version).await?;
self.state = State::SentVersion(Instant::now());
loop {
tokio::select! {
request = tokio::time::timeout(Duration::from_secs(2), self.node_requests.recv()) => {
match request {
Ok(None) => {
return Err(PeerError::Channel);
},
Ok(Some(request)) => {
self.handle_node_request(request).await?;
},
Err(_) => {
// Timeout, do nothing
}
}
},
message = self.actor_receiver.recv() => {
match message {
None => {
return Err(PeerError::Channel);
}
Some(ReaderMessage::Error(e)) => {
return Err(e);
}
Some(ReaderMessage::Message(msg)) => {
self.handle_peer_message(msg).await?;
}
}
}
}
// ...
if self.shutdown {
return Ok(());
}
// If we send a ping and our peer doesn't respond in time, disconnect
if let Some(when) = self.last_ping {
if when.elapsed().as_secs() > PING_TIMEOUT {
return Err(PeerError::PingTimeout);
}
}
// Send a ping to check if this peer is still good
let last_message = self.last_message.elapsed().as_secs();
if last_message > SEND_PING_TIMEOUT {
if self.last_ping.is_some() {
continue;
}
let nonce = rand::random();
self.last_ping = Some(Instant::now());
self.write(NetworkMessage::Ping(nonce)).await?;
}
// divide the number of messages by the number of seconds we've been connected,
// if it's more than 10 msg/sec, this peer is sending us too many messages, and we should
// disconnect.
let msg_sec = self
.messages
.checked_div(Instant::now().duration_since(self.start_time).as_secs())
.unwrap_or(0);
if msg_sec > 10 {
error!(
"Peer {} is sending us too many messages, disconnecting",
self.id
);
return Err(PeerError::TooManyMessages);
}
if let State::SentVersion(when) = self.state {
if Instant::now().duration_since(when) > Duration::from_secs(10) {
return Err(PeerError::UnexpectedMessage);
}
}
}
}-
Handling Node Requests: The method uses a
futures::select!block to listen for requests fromUtreexoNodeviaself.node_requests, with a 10-second timeout for each operation.- If a request is received, it is passed to the
handle_node_requestmethod for processing. - If the channel is closed (
Ok(None)), the method exits with aPeerError::Channel. - If the timeout expires without receiving a request, the method simply does nothing, allowing the loop to continue.
- If a request is received, it is passed to the
-
Processing Peer Messages: Simultaneously, the loop listens for messages from the TCP actor via
self.actor_receiver. Depending on the type of message received:- Error: If an error is reported (closed channel or
ReaderMessage::Error), the loop exits with the error. - Message: Peer messages are processed by the
handle_peer_messagemethod.
- Error: If an error is reported (closed channel or
// Path: floresta-wire/src/p2p_wire/peer.rs
async fn peer_loop_inner(&mut self) -> Result<()> {
// send a version
let version = peer_utils::build_version_message(self.our_user_agent.clone());
self.write(version).await?;
self.state = State::SentVersion(Instant::now());
loop {
tokio::select! {
request = tokio::time::timeout(Duration::from_secs(2), self.node_requests.recv()) => {
match request {
Ok(None) => {
return Err(PeerError::Channel);
},
Ok(Some(request)) => {
self.handle_node_request(request).await?;
},
Err(_) => {
// Timeout, do nothing
}
}
},
message = self.actor_receiver.recv() => {
match message {
None => {
return Err(PeerError::Channel);
}
Some(ReaderMessage::Error(e)) => {
return Err(e);
}
Some(ReaderMessage::Message(msg)) => {
self.handle_peer_message(msg).await?;
}
}
}
}
// ...
if self.shutdown {
return Ok(());
}
// If we send a ping and our peer doesn't respond in time, disconnect
if let Some(when) = self.last_ping {
if when.elapsed().as_secs() > PING_TIMEOUT {
return Err(PeerError::PingTimeout);
}
}
// Send a ping to check if this peer is still good
let last_message = self.last_message.elapsed().as_secs();
if last_message > SEND_PING_TIMEOUT {
if self.last_ping.is_some() {
continue;
}
let nonce = rand::random();
self.last_ping = Some(Instant::now());
self.write(NetworkMessage::Ping(nonce)).await?;
}
// ...
// divide the number of messages by the number of seconds we've been connected,
// if it's more than 10 msg/sec, this peer is sending us too many messages, and we should
// disconnect.
let msg_sec = self
.messages
.checked_div(Instant::now().duration_since(self.start_time).as_secs())
.unwrap_or(0);
if msg_sec > 10 {
error!(
"Peer {} is sending us too many messages, disconnecting",
self.id
);
return Err(PeerError::TooManyMessages);
}
if let State::SentVersion(when) = self.state {
if Instant::now().duration_since(when) > Duration::from_secs(10) {
return Err(PeerError::UnexpectedMessage);
}
}
}
}-
Shutdown Check: The loop continually checks if the
shutdownflag is set. If it is, the loop exits gracefully. -
Ping Management: To maintain the connection, the method sends periodic
NetworkMessage::Pings. If the peer fails to respond within a timeout (PING_TIMEOUT), the connection is terminated. Additionally, if no messages have been exchanged for a period (SEND_PING_TIMEOUT), a new ping is sent, and the timestamp is updated.
Currently, we disconnect if a peer doesn't respond to a ping within 30 seconds, and we send a ping 60 seconds after the last message.
// Path: floresta-wire/src/p2p_wire/peer.rs const PING_TIMEOUT: u64 = 30; const SEND_PING_TIMEOUT: u64 = 60;
// Path: floresta-wire/src/p2p_wire/peer.rs
async fn peer_loop_inner(&mut self) -> Result<()> {
// send a version
let version = peer_utils::build_version_message(self.our_user_agent.clone());
self.write(version).await?;
self.state = State::SentVersion(Instant::now());
loop {
tokio::select! {
request = tokio::time::timeout(Duration::from_secs(2), self.node_requests.recv()) => {
match request {
Ok(None) => {
return Err(PeerError::Channel);
},
Ok(Some(request)) => {
self.handle_node_request(request).await?;
},
Err(_) => {
// Timeout, do nothing
}
}
},
message = self.actor_receiver.recv() => {
match message {
None => {
return Err(PeerError::Channel);
}
Some(ReaderMessage::Error(e)) => {
return Err(e);
}
Some(ReaderMessage::Message(msg)) => {
self.handle_peer_message(msg).await?;
}
}
}
}
if self.shutdown {
return Ok(());
}
// If we send a ping and our peer doesn't respond in time, disconnect
if let Some(when) = self.last_ping {
if when.elapsed().as_secs() > PING_TIMEOUT {
return Err(PeerError::PingTimeout);
}
}
// Send a ping to check if this peer is still good
let last_message = self.last_message.elapsed().as_secs();
if last_message > SEND_PING_TIMEOUT {
if self.last_ping.is_some() {
continue;
}
let nonce = rand::random();
self.last_ping = Some(Instant::now());
self.write(NetworkMessage::Ping(nonce)).await?;
}
// ...
// divide the number of messages by the number of seconds we've been connected,
// if it's more than 10 msg/sec, this peer is sending us too many messages, and we should
// disconnect.
let msg_sec = self
.messages
.checked_div(Instant::now().duration_since(self.start_time).as_secs())
.unwrap_or(0);
if msg_sec > 10 {
error!(
"Peer {} is sending us too many messages, disconnecting",
self.id
);
return Err(PeerError::TooManyMessages);
}
if let State::SentVersion(when) = self.state {
if Instant::now().duration_since(when) > Duration::from_secs(10) {
return Err(PeerError::UnexpectedMessage);
}
}
}
}-
Rate Limiting: The method calculates the rate of messages received from the peer. If the peer sends more than 10 messages per second on average, it is deemed misbehaving, and the connection is closed.
-
Handshake Timeout: If the peer does not respond to the version message within 10 seconds, the loop exits with an error, as the expected handshake flow was not completed.
Handshake Process
In this Peer execution loop we have also seen a State type, stored in the Peer.state field. This represents the state of the handshake with the peer:
// Path: floresta-wire/src/p2p_wire/peer.rs
enum State {
None,
SentVersion(Instant),
SentVerack,
Connected,
}None is the initial state when the Peer is created, but shortly after that it will be updated with SentVersion, when we initiate the handshake by sending our NetworkMessage::Version.
If the peer is responsive, we will hear back from her within the next 10 seconds, via her NetworkMessage::Version, which will be handled by the handle_peer_message (that we saw in the third step). This method will internally save data from the peer, send her a NetworkMessage::Verack (i.e., the acknowledgment of her message), and update the state to SentVerack.
Finally, when we receive the NetworkMessage::Verack from the peer, we can switch to the Connected state, and communicate the new peer data with UtreexoNode.
Node Communication Lifecycle
Once connected to a peer, UtreexoNode can send requests and receive responses.
-
It interacts with a specific peer through
NodeCommon.peersand usesLocalPeerView.channelto send requests. -
Peerreceives the request message and handles it viahandle_node_request(that we saw in the second step). This method will perform the write operation. -
When the peer responds with a message, it is received via the message
actor_receiverand handled by thehandle_peer_messagemethod, which likely passes new data back toUtreexoNode, continuing the communication loop.
Running Floresta
So far in the Floresta journey we have mostly learned about the two core library crates: floresta-chain and floresta-wire.
In Chapter 1 we went over the common library (floresta-common), the three extra libraries (floresta-watch-only, floresta-compact-filters, and floresta-electrum) and the floresta meta-crate. We also mentioned floresta-rpc and floresta-node, the libraries powering our two current binaries.
This chapter puts it all together leveraging the assembler library floresta-node, which provides:
-
The
Florestadstruct: the "orchestrator" that starts the node, spawning asynchronous tasks for each subsystem (theUtreexoNode, an optional JSON-RPC server, the Electrum server, etc.). It also sends the stop signal when requested to, as the main loop inflorestadkeeps checking for aCtrl+Csignal. -
The
Configtype: a single configuration struct used to bootstrapFlorestad.
Floresta Daemon
The florestad binary is the entry point for running a Floresta node. It parses the CLI arguments, builds a Config, and optionally daemonizes the process if the --daemon flag is set. Once initialization is complete, it hands control to Florestad::start, which actually launches the node and all its subsystems.
We'll first look at how the binary sets things up, and then we'll dive into Florestad::start itself to see how the node comes alive.
Florestad
The very first thing we do in the florestad main function is parsing any CLI argument and create the actual data directory, if not already present. Then, we build the Config from the CLI arguments and try to daemonize the process.
Also, if logging to stdout or a file is enabled, we call init_logging to initialize a tracing subscriber. This subscriber may also include tokio-console (a utility from the Tokio project that lets you inspect all running async tasks in real time) if you run florestad with the tokio-console feature. You can learn more about tokio console usage in the Floresta doc folder.
After that, we spawn a process that waits for the Ctrl+C signal, and when it's read this task writes true to the signal variable (an Arc<RwLock<bool>>).
// Path: ../bin/florestad/src/main.rs
fn main() {
let params = Cli::parse();
// If not provided defaults to `$HOME/.floresta`. Uses a subdirectory for non-mainnet networks.
let data_dir = data_dir_path(params.data_dir, params.network);
// Create the data directory if it doesn't exist
fs::create_dir_all(&data_dir).unwrap_or_else(|e| {
eprintln!("Could not create data dir {data_dir:?}: {e}");
exit(1);
});
let config = Config {
data_dir,
// Setting the config from the CLI arguments
// ...
disable_dns_seeds: params.connect.is_some() || params.disable_dns_seeds,
network: params.network,
debug: params.debug,
cfilters: !params.no_cfilters,
proxy: params.proxy,
assume_utreexo: !params.no_assume_utreexo,
connect: params.connect,
wallet_xpub: params.wallet_xpub,
config_file: params.config_file,
#[cfg(unix)]
log_to_file: params.log_to_file || params.daemon,
#[cfg(not(unix))]
log_to_file: params.log_to_file,
assume_valid: params.assume_valid,
log_to_stdout: true,
#[cfg(feature = "zmq-server")]
zmq_address: params.zmq_address,
#[cfg(feature = "json-rpc")]
json_rpc_address: params.rpc_address,
generate_cert: params.generate_cert,
wallet_descriptor: params.wallet_descriptor,
filters_start_height: params.filters_start_height,
user_agent: env!("USER_AGENT").to_owned(),
assumeutreexo_value: None,
electrum_address: params.electrum_address,
enable_electrum_tls: params.enable_electrum_tls,
electrum_address_tls: params.electrum_address_tls,
tls_cert_path: params.tls_cert_path,
tls_key_path: params.tls_key_path,
allow_v1_fallback: params.allow_v1_fallback,
backfill: !params.no_backfill,
};
#[cfg(unix)]
if params.daemon {
// Daemonizing the process
// ...
let mut daemon = Daemonize::new();
if let Some(pid_file) = params.pid_file {
daemon = daemon.pid_file(pid_file);
}
daemon.start().expect("Failed to daemonize");
}
let mut _log_guard: Option<WorkerGuard> = None;
if config.log_to_stdout || config.log_to_file {
let dir = &config.data_dir;
// Initialize logging (stdout/file) per config and retain the file guard
_log_guard = init_logging(dir, config.log_to_file, config.log_to_stdout, config.debug)
.unwrap_or_else(|e| {
eprintln!("Logging file couldn't be created at {dir:?}: {e}");
exit(1);
});
}
let _rt = tokio::runtime::Builder::new_multi_thread()
// Setting the runtime
// ...
.enable_all()
.worker_threads(4)
.max_blocking_threads(2)
.thread_keep_alive(Duration::from_secs(60))
.thread_name("florestad")
.build()
.unwrap();
let signal = Arc::new(RwLock::new(false));
let _signal = signal.clone();
_rt.spawn(async move {
// This is used to signal the runtime to stop gracefully.
// It will be set to true when we receive a Ctrl-C or a stop signal.
tokio::signal::ctrl_c().await.unwrap();
let mut sig = signal.write().await;
*sig = true;
});
let florestad = Florestad::from(config);
_rt.block_on(async {
florestad.start().await.unwrap_or_else(|e| {
eprintln!("Failed to start florestad: {e}");
exit(1);
});
// wait for shutdown
loop {
if florestad.should_stop().await || *_signal.read().await {
info!("Stopping Floresta");
florestad.stop().await;
let _ = timeout(Duration::from_secs(10), florestad.wait_shutdown()).await;
break;
}
sleep(Duration::from_secs(5)).await;
}
});
// drop them outside the async block, so we won't cause a nested drop of the runtime
// due to the rpc server, causing a panic.
drop(florestad);
drop(_rt);
drop(_log_guard); // flush file logs on exit
}Last of all, we build the Florestad instance, and call Florestad::start to start the node. From this point on, we keep checking for the stop signal. If it's found to be true, we call Florestad::stop, which simply replays the signal to the UtreexoNode, so it will "know" when to shut down (we saw how UtreexoNode::new required a kill signal in Chapter 6.2).
CLI Options
You can take a look at the florestad/cli.rs file to see the exact CLI arguments that are supported, or run cargo run --bin florestad -- --help to see the help message.
One particularly useful option is --proxy, which routes all P2P traffic, as well as DNS seed lookups, through a SOCKS5 proxy such as Tor:
# start the daemon with the Tor proxy
florestad --proxy 127.0.0.1:9050
You may also want to disable Assume-Utreexo, the UTXO set snapshot sync we discussed in Chapter 5, which is enabled by default:
# start syncing from the genesis block
florestad --no-assume-utreexo
It's highly recommended to take a look at the Floresta doc folder, where many more details about building, running and testing Floresta are available.
Florestad::start
As we have just mentioned, Florestad and its methods are implemented in the floresta-node "assembler" library. The Florestad::start method is where the node actually comes alive. It wires up the subsystems (watch-only wallet, the UtreexoNode, Electrum server, JSON-RPC server, etc.), and then spawns their asynchronous loops.
At a high level, the method:
- Validates the data directory.
- Loads the watch-only wallet.
- Loads the blockchain database and optional compact filters.
- Builds a
UtreexoNodeConfigand starts theUtreexoNode. - Optionally starts ZMQ, JSON-RPC, and Electrum servers.
- Spawns background tasks and returns.
Let’s walk through the important steps.
First, the data directory is ensured to exist and be writable, or else this library function returns error (note the florestad binary creates such directory).
// Path: floresta-node/src/florestad.rs
/// Actually runs florestad, spawning all modules and waiting until
/// someone asks to stop.
///
/// This function will return an error if the configured data directory path is not an
/// **existing and writable directory**, or cannot be validated as such.
pub async fn start(&self) -> Result<(), FlorestadError> {
let data_dir = &self.config.data_dir;
// Check that the directory exists and is writable
Florestad::validate_data_dir(data_dir)?;Then the watch-only wallet is loaded, and most importantly, the blockchain database (as an Arc<ChainState<FlatChainStore>>):
let blockchain_state = Arc::new(Self::load_chain_state(
data_dir.clone(),
self.config.network,
assume_valid,
)?);If the compact filters feature is enabled, the filter store is initialized. With all these Config values, the UtreexoNodeConfig we saw at Chapter 6.2 is assembled and the UtreexoNode is created:
// Chain Provider (p2p)
let chain_provider = UtreexoNode::<_, RunningNode>::new(
config,
blockchain_state.clone(),
Arc::new(tokio::sync::Mutex::new(Mempool::new(acc, 300_000_000))),
cfilters.clone(),
kill_signal.clone(),
AddressMan::default(),
)
.map_err(|e| FlorestadError::CouldNotCreateChainProvider(format!("{e}")))?;The UtreexoNode instance we create uses the RunningNode context. As we explained in Chapter 6.1:
RunningNodeis the top-level context. When aUtreexoNodeis first created, it will internally switch to the other contexts as needed, and then return toRunningNode. In practice, this makesRunningNodethe default context used byflorestadto run the node.
After that, optional subsystems like ZMQ, JSON-RPC, and Electrum are instantiated. Finally, we spawn the task that runs UtreexoNode<_, RunningNode>::run, which is the main loop of the node.
Summary
At this point, we've seen how the florestad binary works: it parses configuration, optionally daemonizes, and then calls Florestad::start, which orchestrates the watch-only wallet, the actual UtreexoNode, and optional servers.
In the next section, we'll look at the other binary in the Floresta project, floresta-cli: a lightweight command-line client that interacts with the daemon over JSON-RPC.
Floresta-CLI
floresta-cli is a thin CLI that talks to florestad's JSON-RPC server. It uses a simple JSON-RPC client that can call any method defined by the FlorestaRPC trait from floresta-rpc.
Floresta-rpc Traits
The floresta-rpc library defines two traits: FlorestaRPC and JsonRPCClient.
FlorestaRPClists all methods exposed by theflorestadJSON-RPC server.JsonRPCClientis implemented by clients, requiring only a singlecallmethod.
// Path: floresta-rpc/src/rpc.rs
/// A trait specifying all possible methods for floresta's json-rpc
pub trait FlorestaRPC {
/// Get the BIP158 filter for a given block height
///
/// BIP158 filters are a compact representation of the set of transactions in a block,
/// designed for efficient light client synchronization. This method returns the filter
/// for a given block height, encoded as a hexadecimal string.
/// You need to have enabled block filters by setting the `blockfilters=1` option
fn get_block_filter(&self, height: u32) -> Result<String>;
// ...Any type that implements JsonRPCClient will automatically implement FlorestaRPC, which makes this RPC interface available to any client implementation.
Many of the FlorestaRPC methods mirror Bitcoin Core's RPC interface, but with changes that reflect our pruned and utreexo-based design. There are also utreexo-specific methods like get_roots. You can list all available RPC methods by running:
cargo run --bin floresta-cli -- --help
JSON-RPC Client
floresta-cli uses a simple client that is also defined in floresta-rpc, available via the default with-jsonrpc feature. It is implemented as a simple wrapper around the jsonrpc library, which implements the mentioned JsonRPCClient trait, and by extension, FlorestaRPC.
// Path: floresta-rpc/src/jsonrpc_client.rs
// Define a Client struct that wraps a jsonrpc::Client
#[derive(Debug)]
pub struct Client(jsonrpc::Client);// Path: floresta-rpc/src/jsonrpc_client.rs
// Implement the JsonRPCClient trait for Client
impl JsonRPCClient for Client {
fn call<T: for<'a> serde::de::Deserialize<'a> + Debug>(
&self,
method: &str,
params: &[serde_json::Value],
) -> Result<T, crate::rpc_types::Error> {
self.rpc_call(method, params)
}
}Usage
To use floresta-cli, you first need to start florestad with the json-rpc feature enabled (already enabled by default). Once the daemon is running, you can issue commands like:
# Rescan from height 100 to 200
floresta-cli rescanblockchain 100 200
# Get the current blockchain info
floresta-cli getblockchaininfo
For more details about the floresta-cli usage and RPC commands, you can check the Floresta doc folder.
Appendix
The following sections contain reference material that you may find useful for better understanding the Floresta project.
Apendix A: FlatChainStore Architecture
As introduced in Chapter 2, the default Floresta ChainStore implementation, which is in charge of persisting the pruned blockchain and state data, is FlatChainStore.
The "flat" in the name reflects that the store consists solely of raw .bin files, where the serialized data is simply written at different locations. Then, we create a memory-map that allows us to read and write to these files as if they were in memory.
On-Disk Layout
FlatChainStore takes advantage of two observations about the blockchain data that our pruned node stores:
-
Header lookups by height are trivially positional in a flat file. If the raw file is just a header vector, we can fetch the header at any height
hby reading the vector element at that position (i.e., doingheaders[h]but with a memory-mapped file). -
Header lookups by hash can work the same way, but with the intermediate step of getting the corresponding height (via a hash → height map). Once we have the height we can index the flat file vector as before.
Leveraging these facts, FlatChainStore splits the chain data across five plain files:
chaindata/
├─ headers.bin # mmap‑ed vector<HashedDiskHeader>
├─ fork_headers.bin # mmap‑ed vector<HashedDiskHeader> for fork chains
├─ blocks_index.bin # mmap‑ed vector<u32>, accessed via a hash‑map linking block hashes to heights
│
├─ accumulators.bin # plain file (roots blob, var‑len records)
└─ metadata.bin # mmap‑ed Metadata struct (version, checksums, file lengths...)Headers
We store the headers as a HashedDiskHeader, which consists of a DiskBlockHeader (the Floresta type we saw in Chapter 2) and its BlockHash, along with the file position and length of the corresponding accumulator.
// Path: floresta-chain/src/pruned_utreexo/flat_chain_store.rs
#[repr(C)]
#[derive(Debug, Copy, Clone)]
/// To avoid having to sha256 headers every time we retrieve them, we store the hash along with
/// the header, so we just need to compare the hash to know if we have the right header
struct HashedDiskHeader {
/// The actual header with contextually relevant information
header: DiskBlockHeader,
/// The hash of the header
hash: BlockHash,
/// Where in the accumulator file this block's accumulator is
acc_pos: u32,
/// The length of the block's accumulator
acc_len: u32,
}Each header can be accessed via simple pointer arithmetics, given the pointer at the start of the file and the desired header index: header_ptr = start_ptr + index * sizeof(HashedDiskHeader). Depending on the header chain status (mainchain or fork), we will store the header on either headers.bin or fork_headers.bin.
- In the
headers.binfile, the file index is the same as the height. - However, in
fork_headers.bin, the file index is different from the height, as the fork block headers can be from multiple chains.
Blocks Index
Then we have the blocks index, the persistent block hash → index hash-map. We use a short (non-cryptographic) hash function to map a BlockHash to a u32 index. Any collision is solved by looking up the HashedDiskHeader with the found index, and checking whether the stored hash is the hash we want. Otherwise, if the found index is not the desired one and is not a vacant position, we linearly probe the next position.
// Path: floresta-chain/src/pruned_utreexo/flat_chain_store.rs
/// Returns the position inside the hash map where a given hash should be
///
/// This function computes the short hash for the block hash and looks up the position inside
/// the index map. If the found index fetches the header we are looking for, return this bucket.
/// Otherwise, we continue incrementing the short hash until we either find the record or a
/// vacant position. If you're adding a new entry, call this function (it will return a vacant
/// position) and write the height there.
unsafe fn hash_map_find_pos(
&self,
block_hash: BlockHash,
get_header_by_index: impl Fn(Index) -> Result<HashedDiskHeader, FlatChainstoreError>,
) -> Result<IndexBucket, FlatChainstoreError> {
let mut hash = Self::index_hash_fn(block_hash) as usize;
// Retrieve the base pointer to the start of the memory-mapped index
let base_ptr = self.index_map.as_ptr() as *mut Index;
// Since the size is a power of two `2^k`, subtracting one gives a 0b111...1 k-bit mask
let mask = self.index_size - 1;
for _ in 0..self.index_size {
// Obtain the bucket's address by adding the masked hash to the base pointer
// SAFETY: the masked hash is lower than the `index_size`
let entry_ptr = base_ptr.add(hash & mask);
// If this is the first time we've accessed this pointer, this candidate index is 0
let candidate_index = *entry_ptr;
// ...
// If the header at `candidate_index` matches `block_hash`, this is the target bucket
let file_header = get_header_by_index(candidate_index)?;
if file_header.hash == block_hash {
return Ok(IndexBucket::Occupied {
ptr: entry_ptr,
header: file_header.header,
});
}
// If we find an empty index, this bucket is where the entry would be added
// Note: The genesis block doesn't reach this point, as its header hash is matched
if candidate_index.is_empty() {
return Ok(IndexBucket::Empty { ptr: entry_ptr });
}
// If no match and bucket is occupied, continue probing the next bucket
hash = hash.wrapping_add(1);
// ...
}
// If we reach here, it means the index is full. We should re-hash the map
Err(FlatChainstoreError::IndexIsFull)
}Thanks to the blocks index, we can fetch a header via its hash (hash → height → header):
- We get the index for that
BlockHash, which is tagged to indicate whether the block is mainchain or in a fork. - Then, we use the index to fetch the corresponding header from
headers.binorfork_headers.bin.
In fact, since the hash-map fetches the file HashedDiskHeader to verify this index is the correct one, and not a collision, the hash → height function returns the header "for free."
Accumulators and Metadata
The accumulators.bin file follows a similar approach as the two header files, except each accumulator has a variable length encoding. We have a distinct accumulator after processing each block, so we can store all of them sequentially and, in the rare case of a reorg, roll back to a previous accumulator (i.e., the accumulator for the fork point). We reorg our accumulator state simply by truncating the accumulators.bin file, and then continue appending the new block accumulators.
Because file access is only required for loading the last accumulator state (at node startup) and for reorging the chain, we don't really need to memory-map this file.
To be more precise, storing all the accumulators is not required nor ideal, especially for ancient blocks that become harder and harder to reorg. The optimal solution here is a sparse forest, where we keep fewer and fewer accumulators as we go back in block height. We only keep all the accumulators for the last few blocks because deeper reorgs are exponentially less likely. In the rare case of a deep reorg, we would still be able to recover the fork point accumulator by re-processing the blocks after the last accumulator that we have.
Finally, we have the metadata.bin file, which stores the serialized Metadata struct. This metadata contains the FlatChainStore magic number and version, the allocated lengths for the rest of files, and stuff like a checksum for them, to verify integrity each time we load the store.
LRU Cache
Furthermore, to speed up repetitive header lookups, FlatChainStore maintains a least-recently-used (LRU) cache that maps block hashes to headers for quick access. The default size for the cache is 10,000 block headers.
Below is the actual type definition, where MmapMut is the mutable memory-mapped file type from the memmap2 crate, BlockIndex is a wrapper over the memory-mapped index file (that handles the block hash → index mapping), and LruCache comes from the lru crate.
// Path: floresta-chain/src/pruned_utreexo/flat_chain_store.rs
pub struct FlatChainStore {
/// The memory map for our headers
headers: MmapMut,
/// The memory map for our metadata
metadata: MmapMut,
/// The memory map for our block index
block_index: BlockIndex,
/// The memory map for our fork files
fork_headers: MmapMut,
/// The file containing the accumulators for each blocks
accumulator_file: File,
/// A LRU cache for the last n blocks we've touched
cache: Mutex<LruCache<BlockHash, DiskBlockHeader>>,
}How big can it get? (Spoiler: comfortably under 1GB)
Below we calculate the worst case size scenario that we could reach in a few decades.
| File | Grows with | Size | Why that cap is safe until ~2055 |
|---|---|---|---|
headers.bin | 1×HashedDiskHeader/block | 320MiB (2.5M × 128B) | 2.5M blocks reached by the year ~2055; if we need more capacity we just mmap a bigger sparse file. |
blocks_index.bin | Fixed bucket array | 40MiB (10M × 4B) | Load factor ~0.3 even at 3M blocks. Should we approach 0.7 we trigger a single re‑hash into a larger map. |
accumulators.bin | 1×(roots blob and a u64 leaves count) each 32 blocks | 80MiB (2.5M / 32 × 1032B) | Assumes a mean of 32 roots (absolute worst case is 64 roots) and keeping one accumulator each 32 blocks. |
fork_headers.bin | 1×HashedDiskHeader/fork block | 2MiB (16k × 128B) | Plenty of room for fork headers storage; we can prune fork headers that are deep enough. |
Real‑world footprint as of July 2025, with most accumulators pruned: 177MiB.
Bottom‑line: The worst case for the next few decades is around 442MiB, meaning we can assume less than 500MiB for the foreseeable future – well below the RAM of any budget laptop.